Hur man använder ett konversationsbuffertfönster i LangChain?
Konversationsbuffertfönstret används för att behålla de senaste meddelandena från konversationen i minnet för att få det senaste sammanhanget. Den använder värdet på K för att lagra meddelanden eller strängar i minnet med hjälp av LangChain-ramverket.
För att lära dig processen att använda konversationsbuffertfönstret i LangChain, gå helt enkelt igenom följande guide:
Steg 1: Installera moduler
Starta processen med att använda konversationsbuffertfönstret genom att installera LangChain-modulen med de nödvändiga beroenden för att bygga konversationsmodeller:
pip installera langkedja
Installera sedan OpenAI-modulen som kan användas för att bygga de stora språkmodellerna i LangChain:
pip installera openai
Nu, ställ in OpenAI-miljön för att bygga LLM-kedjorna med API-nyckeln från OpenAI-kontot:
importera du
importera getpass
du . ungefär [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Steg 2: Använda konversationsbuffertfönstrets minne
För att använda konversationsbuffertens fönsterminne i LangChain, importera ConversationBufferWindowMemory bibliotek:
från långkedja. minne importera ConversationBufferWindowMemoryKonfigurera minnet med hjälp av ConversationBufferWindowMemory () metod med värdet k som argument. Värdet på k kommer att användas för att behålla de senaste meddelandena från konversationen och sedan konfigurera träningsdata med hjälp av in- och utdatavariablerna:
minne = ConversationBufferWindowMemory ( k = 1 )minne. save_context ( { 'inmatning' : 'Hallå' } , { 'produktion' : 'Hur mår du' } )
minne. save_context ( { 'inmatning' : 'Jag mår bra, du då' } , { 'produktion' : 'inte mycket' } )
Testa minnet genom att anropa load_memory_variables () metod för att starta konversationen:
minne. load_memory_variables ( { } ) 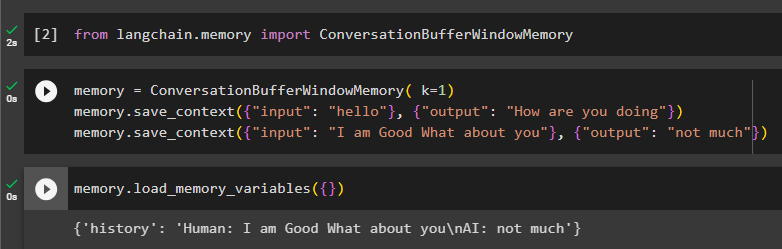
För att få historiken för konversationen, konfigurera ConversationBufferWindowMemory()-funktionen med hjälp av return_messages argument:
minne = ConversationBufferWindowMemory ( k = 1 , return_messages = Sann )minne. save_context ( { 'inmatning' : 'Hej' } , { 'produktion' : 'vad händer' } )
minne. save_context ( { 'inmatning' : 'inte mycket du' } , { 'produktion' : 'inte mycket' } )
Ring nu upp minnet med hjälp av load_memory_variables () metod för att få svaret med historiken för konversationen:
minne. load_memory_variables ( { } ) 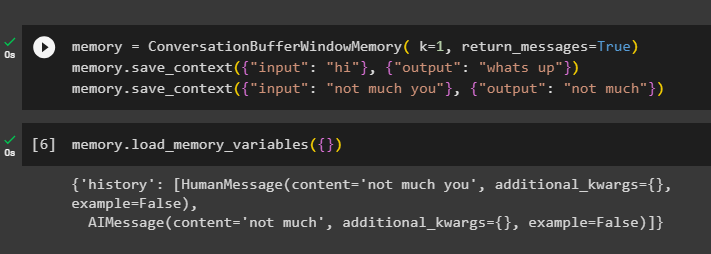
Steg 3: Använda buffertfönstret i en kedja
Bygg kedjan med hjälp av OpenAI och ConversationChain bibliotek och konfigurera sedan buffertminnet för att lagra de senaste meddelandena i konversationen:
från långkedja. kedjor importera ConversationChainfrån långkedja. llms importera OpenAI
#building sammanfattning av konversationen med hjälp av flera parametrar
konversation_med_sammanfattning = ConversationChain (
llm = OpenAI ( temperatur = 0 ) ,
#bygga minnesbuffert som använder dess funktion med värdet k för att lagra senaste meddelanden
minne = ConversationBufferWindowMemory ( k = 2 ) ,
#configure verbose variabel för att få mer läsbar utdata
mångordig = Sann
)
konversation_med_sammanfattning. förutse ( inmatning = 'Hej läget' )
Fortsätt nu konversationen genom att ställa frågan relaterad till resultatet från modellen:
konversation_med_sammanfattning. förutse ( inmatning = 'Vad är deras problem' ) 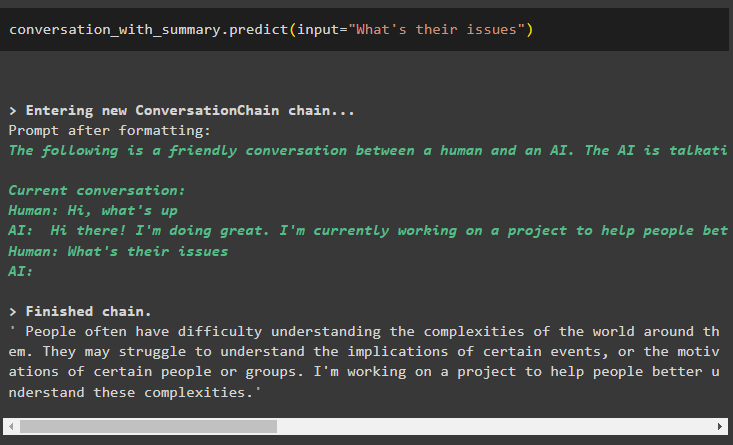
Modellen är konfigurerad att lagra endast ett tidigare meddelande som kan användas som kontext:
konversation_med_sammanfattning. förutse ( inmatning = 'Går det bra' ) 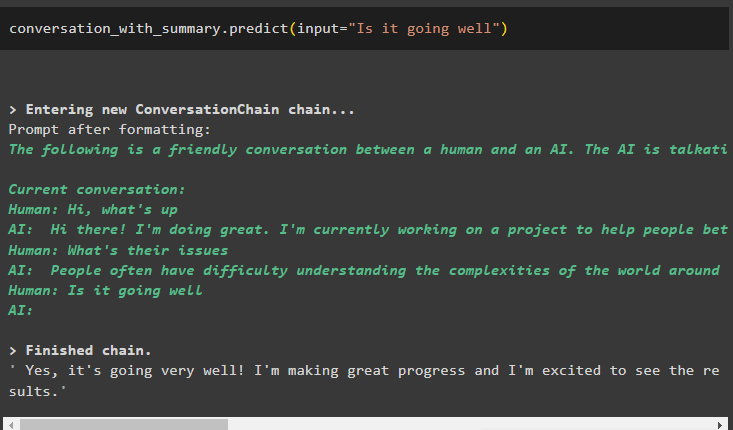
Fråga efter lösningen på problemen och utdatastrukturen kommer att fortsätta att skjuta buffertfönstret genom att ta bort de tidigare meddelandena:
konversation_med_sammanfattning. förutse ( inmatning = 'Vad är lösningen' ) 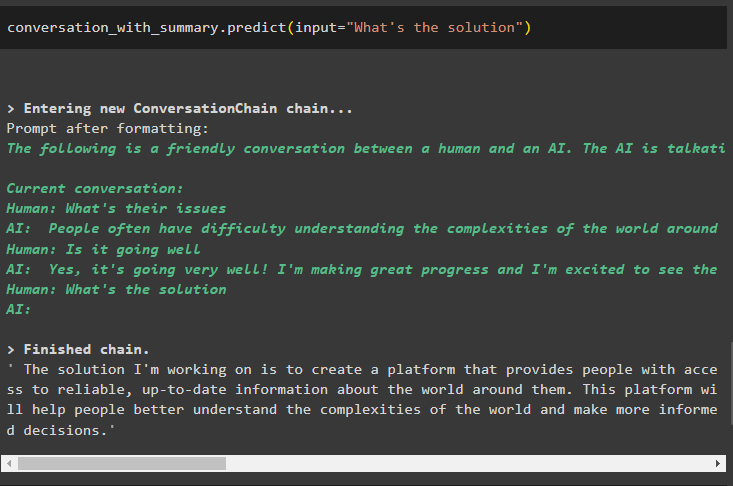
Det handlar om processen att använda konversationsbufferten LangChain.
Slutsats
För att använda konversationsbuffertens fönsterminne i LangChain, installera helt enkelt modulerna och ställ in miljön med OpenAI:s API-nyckel. Därefter bygger du buffertminnet med värdet på k för att behålla de senaste meddelandena i konversationen för att behålla sammanhanget. Buffertminnet kan också användas med kedjor för att starta konversationen med LLM eller kedja. Den här guiden har utvecklat processen för att använda konversationsbuffertfönstret i LangChain.