Pandas Set_Option Method
Idag ska vi titta på hur man använder funktionen 'pd.set_option()' för att visa alla kolumner i Pandas Dataframe när du presenterar den i ditt Spyder-verktyg. För att använda 'pd.set_option()', följer vi den givna syntaxen:

Låt oss börja lära oss konceptet med hjälp av den praktiska implementeringen av Python-programmet.
Exempel: Använder Pandas Set_Option-metoden för att visa alla kolumner
Denna demonstration är en guide för att visa alla kolumner i en DataFrame genom att använda Pandas 'set_option()'. Vi kommer att klargöra detaljerna för varje steg för implementeringen av denna Python-metod.
Det första kravet för den praktiska implementeringen av Python-skriptet är att ta reda på det bästa verktyget där du kör ditt program. Verktyget som vi använde för vår illustration är verktyget 'Spyder'. Vi lanserade verktyget och började arbeta med Python-skriptet.
Från och med koden måste vi initialt importera de förutsättningsbibliotek som vi behöver i det här programmet. Det första biblioteket som vi laddade in i vår Python-fil är Pandas-biblioteket eftersom funktionerna som vi använder här tillhandahålls av Pandas. Vi kallade det här biblioteket som 'pd'. Det andra biblioteket som vi laddade är NumPy-biblioteket. NumPy (Numerical Python) är ett numeriskt datorpaket utvecklat över Python-programmering. Avsnittet Importera NumPy i koden styr Python att integrera NumPy-modulen i din nuvarande Python-fil. 'As np'-delen av skriptet instruerar sedan Python att tilldela NumPy 'np'-förkortningen. Det gör att du kan använda NumPy-metoderna genom att ange 'np.function_name' istället för NumPy.
Nu börjar vi med huvudkoden. Det främsta och grundläggande behovet för vårt program är Pandas DataFrame. Så vi visar alla kolumner den innehåller. Nu är det helt upp till dig om du vill skapa en DataFrame med specificerade värden eller om du behöver importera en CSV-fil. Det vi valde för den här instansen var att skapa en DataFrame med NaN-värden. Vi anropade metoden 'pd.DataFrame()' för att konstruera en DataFrame. Här angav vi två parametrar - 'index' och 'kolumner'. Argumentet 'index' hänvisar till raderna vilket betyder att vi ställer in raderna för DataFrame.
Vi tilldelade parametern 'index' och NumPy-funktionen 'np.arange() med ett värdeantal på '6'. Den genererar sex rader för DataFrame. Den fyller alla poster med NaN-värden eftersom vi inte har försett den med något värde. Argumentet 'kolumner', som namnet anger, används för att ställa in kolumnerna för DataFrame. Den är också tilldelad funktionen 'np.arange()' med '25' värderäkning för kolumnerna. Således konstruerar den 25 kolumner för DataFrame.
Följaktligen, när vi anropar funktionen 'pd.DataFrame()' har vi en DataFrame med 25 kolumner och 6 rader fyllda med nollvärden. För behovet av att bevara denna DataFrame måste vi bygga ett DataFrame-objekt som lagrar dess innehåll. Därför skapade vi ett DataFrame-objekt 'random' och tilldelade det resultatet som vi får från metoden 'pd.DataFrame()'. Nu vill du säkert se DataFrame som genereras. Python ger oss en metod för att se resultatet på skärmen som är 'print()'-funktionen. Vi anropade den här metoden genom att skicka DataFrame-objektet 'random' som parameter.
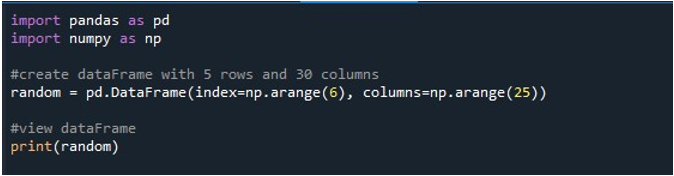
När vi kör det här kodavsnittet får vi vår DataFrame med NaN-värden som visas på terminalen. Här kan vi observera att några av de första kolumnerna och bara några från slutet är synliga. Alla kolumner däremellan är trunkerade. Som standard döljer den några av raderna och kolumnerna för att undvika att skapa frustration för användaren genom att visa enorma datamängder.
Du kan till och med kontrollera antalet totala kolumner i en DataFrame genom att använda 'len()'-funktionen i Pandas. Skriv 'len()'-funktionen på konsolen på ditt 'Spyder'-verktyg. Skriv DataFrames namn mellan dess parentes med egenskapen '.columns'. Den returnerar den totala längden på kolumner i din DataFrame.

Den returnerar längden på vår DataFrame som är 25.
Nu är nästa och kärnuppgift att ändra standardalternativet för att visa utdata. Det kan finnas omständigheter där du vill se hela DataFrame på terminalen. På grund av standardvärdena trunkeras många poster vilket orsakar besvikelse för användaren. Du kommer att lära dig här hur du löser detta problem. Pandas ger oss en 'pd.set_option()'-funktion för att ändra standardinställningarna för visning. Direkt efter att ha visat DataFrame på konsolen anropar vi metoden 'pd.set_option()'. Vi anger parametern mellan parenteserna för denna funktion som vi behöver använda för att visa alla kolumner i DataFrame.
Här använde vi 'display.max_columns' för att visa de maximala kolumnerna i vår DataFrame. Vi kan också definiera värdet för denna parameter, det vill säga de maximala kolumner som du vill visa. Vi, å andra sidan, ställer in 'display.max_columns' till 'None' vilket visar alla kolumner från DataFrame med maximal längd. Slutligen använde vi funktionen 'print()' för att visa den resulterande DataFrame med alla kolumner synliga på terminalen.
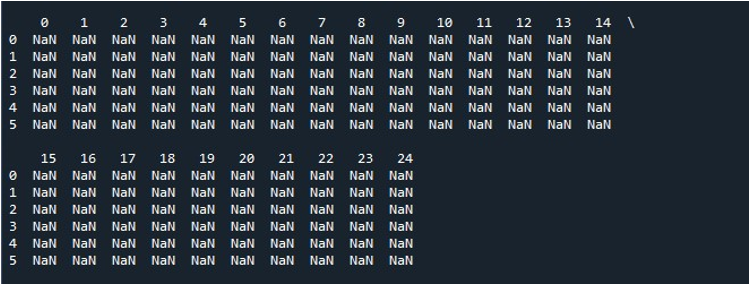
När vi trycker på alternativet 'Kör fil' på verktyget 'Spyder', kan vi se en DataFrame som visas. Denna DataFrame har sex rader och antalet kolumner den innehåller är 25. Det finns inga kolumner som är trunkerade eftersom funktionen 'pd.set_option()' med maximal kolumnlängd är aktiverad nu.
Vi kan till och med återställa visningsalternativet eftersom när vi väl har ställt in visningslängden till maximal, fortsätter den att visa DataFrames med alla kolumner i just den Python-filen. För detta använder vi Pandas 'pd.reset_option()'. Vi anropar denna funktion och tillhandahåller 'display.max_columns' som parameter för denna funktion.

Detta ger oss de första visningsinställningarna för den medföljande DataFrame.
Slutsats
Att se hela resultatet på terminalen med en enorm datauppsättning får oss ibland i problem när verktygets standardinställningar står i kontrast till användarens behov. För att lösa detta bakslag ger Pandas oss metoden 'pd.set_option()'. I den här inlärningsguiden introducerade vi dig till denna metod och behovet av att använda den. Vi demonstrerade ämnet med de praktiskt kompilerade och exekverade Python-exempelkoderna. Vi återgav resultatet av illustrationen på 'Spyder'. Vi förklarade hur man visar alla kolumner i DataFrame på konsolen genom att ändra standardinställningarna samt återställa alla inställningar till initial. Genom att ge en helt fokuserad uppmärksamhet på den praktiska implementeringen av modulen kan du använda den när du stöter på sådana problem.