
Vi kommer att se det praktiska utförandet av denna funktion i denna handledning.
Exempel 1: Använda metoden Pandas Series.Reset_Index() för att återställa indexet för en serie för att behålla den ursprungliga indexlistan som en kolumn
Metoden 'Series.reset_index()' används i den här illustrationen för att återställa indexet för en Pandas-serie och behålla ändringarna i kopian av serien.
Arbetet med Python-programmet började med att hitta ett lämpligt verktyg för vårt system för att följa skriptet. Verktyget 'Spyder' väljs för exekvering av programmen.
Vi initierar skriptet genom att ladda de väsentliga biblioteken först. Eftersom metoden 'Series.reset_index()' används från Pandas verktygslåda, måste vi nödvändigtvis ladda den i vår Python-miljö. Pandas-biblioteket importeras genom att skriva skriptet 'importera pandor som pd'. Avsnittet 'som pd' på den här raden hänvisar till att göra 'pd' till ett alias för 'Pandas'-biblioteket. Därför behöver vi inte använda 'Pandas'. Vi skriver bara 'pd' för att komma åt valfri Pandas-funktion istället.
Den första metoden som vi kommer åt från Pandas-modulen med 'pd'-alias är metoden 'pd.Series'. Denna metod är en Pandas inbyggd metod för att skapa en serie med den tillhandahållna uppsättningen av värden. Vi anropar denna funktion och specificerar värdena som är '34', '21', '18', '45', '76', '82', '22', '40', '91', '101', och '8'. Även namnet på kolumnen definieras med parametern 'name' som 'Data'.
Efter det initierar vi en 'new_index'-variabel och tilldelar den några värden men med samma längd som vi använde för värdena i serien. Värdena för variabeln 'new_index' är 'A01', 'A02', 'A03', 'A04', 'A05', 'A06', 'A07', 'A08', 'A09', 'A10' och 'A11'. Vi använder värdena som lagras i denna variabel för indexet. För att ställa in indexkolumnen för serien anropar vi egenskapen 'Series.index' och tilldelar den variabeln 'new_index'. Värdena som lagras i 'new_index' sätts som index för serien istället för standardlistan för indexet som börjar från '0'. Slutligen, för att se serien med det angivna indexet, anropar vi funktionen 'print()' och skickar serien 'Number' som indata för att skriva ut dess innehåll.
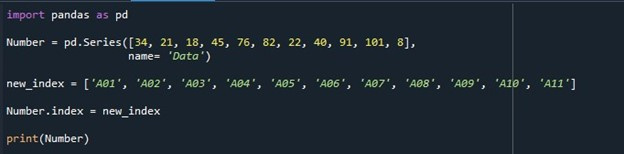
Den resulterande serien med de specificerade indexen som ersatte standardindexlistan visas på terminalen.
För att återställa den här användardefinierade indexlistan till standardlistan använder vi Pandas metoden 'Series.reset_index()'.
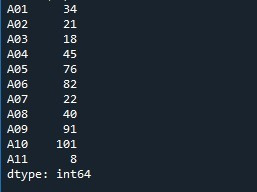
Vi anropar metoden 'Series.reset_index()' för att återställa indexlistan. Seriens namn anges som 'Number' med metoden 'reset_index()'. Således fungerar det genom att kontrollera serien och återställa indexlistan till standardinställningarna. För att spara dessa ändringar skapar vi variabeln 'Output' som genererar en kopia av serien med en ändrad indexlista. Vi använder 'print()'-funktionen för att visa 'output'-innehållet.

I utgångsbilden kan vi se att standard sekventiellt index visas. Dessutom läggs den angivna indexlistan till som en ny kolumn i serien med etiketten 'index'.
Exempel 2: Använda Pandas Series.Reset_Index()-metoden för att återställa indexet för en serie och ta bort det initiala indexet
Den här instansen visar tekniken för att återställa indexet för en Pandas-serie med metoden 'Series.reset_index()'. Dessutom kasserar vi den initialt definierade indexkolumnen med 'drop'-parametern för funktionen 'Series.reset_index()'.
För exekvering av kodavsnittet importerar vi först Pandas-biblioteket som 'pd'. Sedan tränar vi en metod från denna för närvarande laddade Pandas-modul för att skapa en Pandas-serie. Funktionen 'pd.Series()' används och vi tillhandahåller en uppsättning värden till den för att generera en serie med dessa värden. Värdena som vi angav för seriekonstruktionen är av strängdatatyp. Dessa värden är 'Nestle', 'Cadbury', 'Mars', 'Dove', 'Lindt', 'Godiva', 'Ghirardelli' och 'Ferrero'. Vi använder parametern 'name' för att märka denna kolumn. Vi kallar det 'Varumärke' när vi skapar en serie som håller chokladmärkenas namn. Seriens längd är 8. Ett serieobjekt 'Chocolates' skapas och tilldelas resultatet som produceras från anropet av Pandas 'pd.Series()'-metoden.
Dessutom skapas en variabel 'identifierare' och initieras med dessa värden 'A', 'B', 'C', 'D', 'E', 'F', 'G' och 'H'. Längden på värden som den innehåller är densamma som längden på värden för serien. Nu ändrar vi standardindexlistan för serien och tillhandahåller 'identifierare'-variabelns värden som ska användas som index. För att ställa in indexet utövas egenskapen 'Series.index'. Namnet på serien 'choklad' nämns med egenskapen '.index'. Vi tilldelar variabeln 'identifier' till indexegenskapen. Egenskapen 'index' extraherar värdena som bevaras i variabeln 'identifier' och gör dem till indexlistan över serier. Metoden 'print()' anropas slutligen för att skriva ut serien 'choklad'.
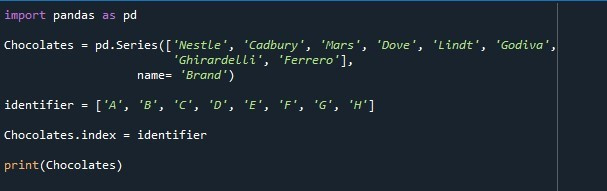
Serien som visas i följande ögonblicksbild visar att vi framgångsrikt placerade den angivna indexlistan istället för standardindexlistan.
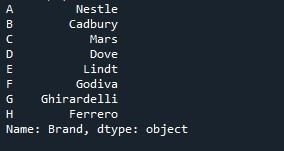
Om du nu vill återställa indexinställningarna, använd helt enkelt Pandas-metoden 'Series.reset_index()'. Vi tillhandahåller vårt serienamn med denna metod. Det återställer bara indexinställningarna till standard för den specifika serien.
Vi anropar metoden 'Series.reset_index()' och tillhandahåller serienamnet som 'choklad'. För att lagra serien med standardindexlistan skapar vi en variabel 'ser'. Nu måste vi se den här serien. För detta används metoden 'print()'. Inom dess klammerparenteser skickar vi 'ser'-variabeln så att den visar allt som denna variabel har bevarat.

Den resulterande serien visas med standardindexlistan. Men också den initialt angivna indexlistan finns som en kolumn i serien med 'index'-titeln. Metoden 'reset_index()' placerar standardindexlistan men den har inte tagit bort den angivna listan för indexet och behåller den som en ny kolumn istället.
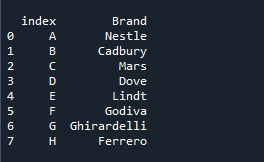
För att ignorera den initialt angivna indexlistan som nu läggs till som en kolumn i serien, använder vi en parameter i metoden 'reset_index()'. Denna parameter är 'drop'. Den tar in det booleska värdet som indata. Som standard är 'drop'-parameterns värde satt till 'False' vilket betyder att den inte släpper den initiala indexlistan. Eftersom vi vill ta bort den ursprungliga indexlistan måste vi ändra dess värde till 'True'.
Vi skickar bara 'drop'-attributet med 'True'-värdet till funktionen 'Series.reset_index()'.

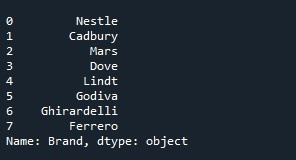
Den renderade utdata visar en serie som nu har tappat kolumnen 'index' och visas med standardindexlistan. Det resulterade resultatet presenteras i följande ögonblicksbild:
Slutsats
Du kan ha de datamängder där din indexlista är specificerad att användas istället för standardindexlistan. Vi kan behöva återställa den till standardinställningarna. Av denna anledning förser Pandas oss med metoden 'Series.reset_index()'. Denna metod ändrar indexet till standardinställningar. Vi tillhandahåller två tekniker för att använda denna metod. För den första illustrationen behöll vi den initialt angivna indexlistan i den resulterande serien som en kolumn efter att ha lagt till standardindexlistan. Den andra tekniken visade hur man släpper den specificerade listan från serien med hjälp av parametern 'drop'.