Låt oss titta på iconv-verktyget för Linux i dess terminalkonsol nu. Så vi har kört instruktionen 'iconv' med flaggan '-l' för att visa alla kända och mest använda kodade teckenuppsättningar på vår terminalskärm. Den kommer att visa de kodade teckenuppsättningarna tillsammans med deras alias. Du kan se en lång lista med kodade teckenuppsättningar efter att ha scrollat ner lite.
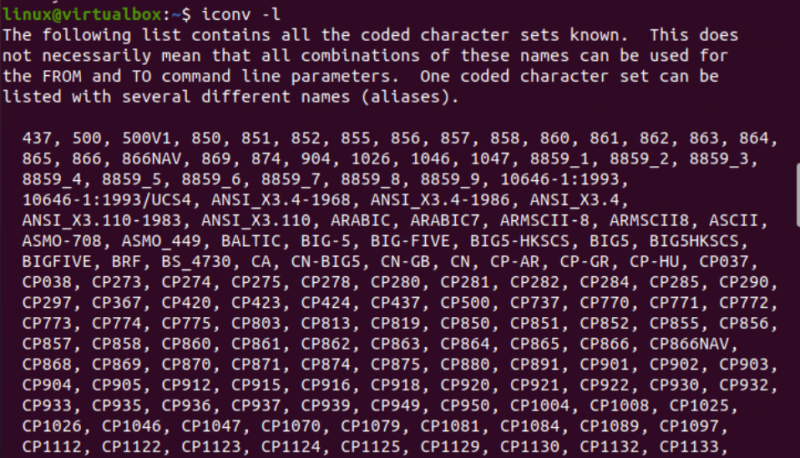
Nu är det dags att komma igång med implementeringen av iconv-kommandot i Linux. För det första behöver vi olika typer av filer i vårt system för att konvertera en typ av fil till en annan typ. Därför använder vi 'touch'-frågan på konsolterminalen för att skapa tre olika filer, dvs Java-typ, C-typ och texttyp. Lista det aktuella kataloginnehållet, hittar du de nyligen genererade filerna i den.
Efter detta kommer vi att titta på typen av varje fil separat med hjälp av 'fil'-frågan tillsammans med namnet på varje fil. Denna fråga behöver alternativet '-I' för att visa typen av kodningsteckenuppsättning för varje fil separat. Om du glömde att använda alternativet '-I', använd '—mime'-flaggan istället. Både flaggorna '-I' och '—mime' fungerar på samma sätt.
Nu, efter att ha kört 'fil'-instruktionen för 'txt'-filen, fick vi teckentypskodningen 'US-ASCII'. Medan du använder samma instruktion för Java- och C-filerna, visar den att båda filerna innehåller 'BINÄR' teckentypskodning. Tillsammans med det visar denna instruktion att alla dessa tre filer är tomma.
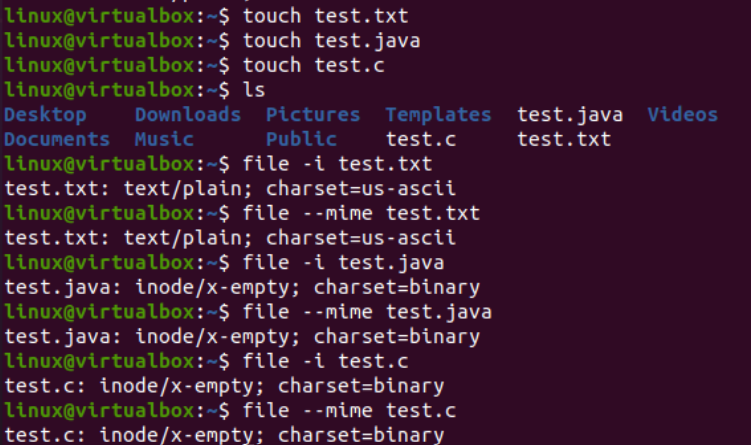
Nu kommer vi att illustrera användningen av iconv-instruktioner på konsolen för att konvertera en specifik teckenuppsättningskodningsfil till en annan teckenuppsättningskodning. Innan dess måste vi lägga till lite kod eller data till våra filer. Därför har vi lagt till Java-koden i filen 'text.java', C-koden i filen 'text.c' och textdata i filen 'test.txt'. Kattfrågan användes här för att visa innehållet i alla tre filerna, som presenteras nedan:
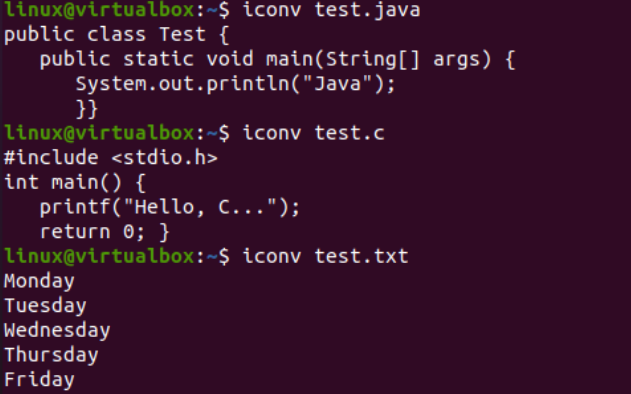
Nu när vi har lagt till data framgångsrikt kommer vi att se teckenuppsättningskodningen för dessa filer igen. Så vi har provat samma filinstruktion i skalet med '-I'-flaggan och filnamnen, dvs test.txt, test.java och test.c. Att köra dessa tre instruktioner separat för alla tre filerna visar att teckenuppsättningskodningen har uppdaterats för Java- och C-filerna medan den förblir densamma för textfilen, dvs US-ASCII. Kodningen av Java- och C-filer var tidigare 'binär'; nu är det 'US-ASCII'. Det visar också att textfilen innehåller vanlig textdata medan de andra två kodfilerna innehåller skripten som innehåll.

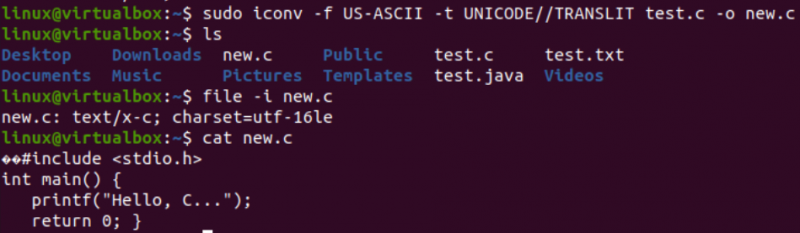
Det är dags att utföra den faktiska uppgiften som behövs för den här artikeln, d.v.s. konvertera en kodning till en annan med hjälp av iconv-kommandot i skalet. Således har vi använt 'iconv'-instruktionen i skalterminalen med 'sudo'-privilegierna. Detta kommando tar alternativet '-f' står för 'från', och alternativet '-t' står för 'till', dvs från en kodning till en annan.
Efter alternativet '-f' måste du ange kodningen som din fil redan har, dvs US-ASCII. Efter alternativet '-t' måste du ange den kodning du vill ersätta med den gamla kodningen, dvs UNICODE. Du måste ange namnet på en fil som används som källa med alternativet –o för att skapa dess objektbild. Objektbilden skulle vara en annan fil, d.v.s. 'new.c', av samma typ men med den nya kodningen och samma data.
Efter att ha utfört följande instruktion kommer du att få en ny fil i samma katalog, d.v.s. enligt 'ls'-frågan. Nu kommer vi att leta efter teckenuppsättningskodningen för en ny fil som genereras med hjälp av iconv-instruktionen. Vi kommer återigen att använda 'fil'-instruktionen med alternativet '-I' och det nya filnamnet, d.v.s. new.c.
Du kommer att se att teckenuppsättningen för den här nya filen har varit annorlunda än teckenuppsättningen för en gammal fil, det vill säga teckenuppsättningen UTF-16LE. Detta beror på att vi har översatt US-ASCII-kodningen till UNICODE-kodningen med hjälp av iconv-instruktionen för vår new.c-fil. 'cat'-frågan visade samma C-kod i filen men började med några Unicode-tecken, som redan presenterats.
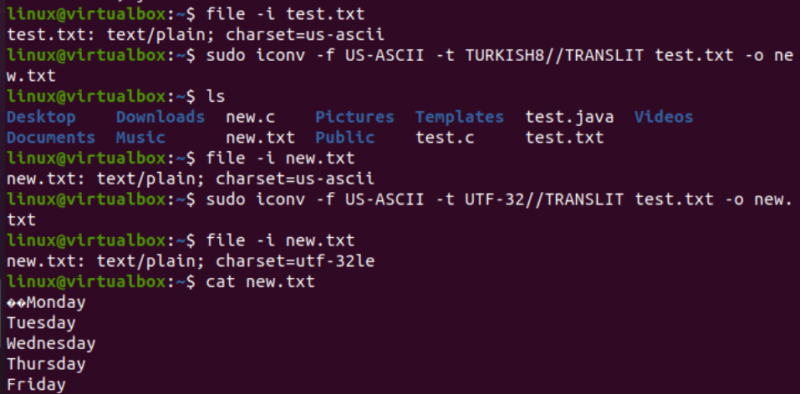
På ett mycket liknande sätt kommer vi att ändra kodningen av textfilen test.txt. Filinstruktionen visar att den har en US-ASCII teckenuppsättningskodning. Kommandot iconv har använts med samma format för att konvertera kodningen av filen test.txt från US-ASCII till TURKISH8. Du kommer att se att det inte ändrar US-ASCII till turkiska.
Efter detta använde vi samma kommando för att täcka US-ASCII till UTF-32 teckenuppsättningskodning för samma fil. Den här gången fungerar det. Detta beror på att det ibland kan uppstå problem med att konvertera en kodningsuppsättning till en annan, eller att den andra kodningen kanske inte stöder det.
Slutsats
Den här artikeln diskuterade hur man använder iconv Linux-instruktionerna för att konvertera en kodningsteckenuppsättning till en annan med deras alias. På detta sätt var vi tvungna att skapa några filer av olika typer.