Förutsättningar
Du måste installera databasservern med klienten innan du övar på exemplen i denna handledning. MariaDB-databasservern och -klienten används i denna handledning.
1. Kör följande kommandon för att uppdatera systemet:
$ sudo apt-get uppdatering
2. Kör följande kommando för att installera MariaDB-servern och klienten:
$ sudo apt-get installera mariadb-server mariadb-client
3. Kör följande kommando för att installera säkerhetsskriptet för MariaDB-databasen:
$ sudo mysql_secure_installation
4. Kör följande kommando för att starta om MariaDB-servern:
$ sudo /etc/init.d/mariadb starta om
6. Kör följande kommando för att logga in på MariaDB-servern:
$ sudo mariadb -u rot -sLista över exempel på SQL-frågor
- Skapa databasen
- Skapa tabellerna
- Byt namn på tabellnamnet
- Lägg till en ny kolumn i tabellen
- Ta bort kolumnen från tabellen
- Infoga en enda rad i tabellen
- Infoga flera rader i tabellen
- Läs alla särskilda fält från tabellen
- Läs tabellen efter att ha filtrerat data från tabellen
- Läs tabellen efter att ha filtrerat data baserat på boolesk logik
- Läs tabellen efter att ha filtrerat raderna baserat på dataintervallet
- Läs tabellen efter att ha sorterat tabellen baserat på de specifika kolumnerna.
- Läs tabellen genom att ställa in det alternativa namnet på kolumnen
- Räkna det totala antalet rader i tabellen
- Läs data från flera tabeller
- Läs tabellen genom att gruppera de särskilda fälten
- Läs tabellen efter att du har utelämnat dubblettvärdena
- Läs tabellen genom att begränsa radnumret
- Läs tabellen baserat på den partiella matchningen
- Räkna summan av det särskilda fältet i tabellen
- Hitta maximi- och minimivärden för det särskilda fältet
- Läs data om den särskilda delen av ett fält
- Läs tabelldata efter sammankoppling
- Läs tabelldata efter matematisk beräkning
- Skapa en vy av tabellen
- Uppdatera tabellen baserat på det särskilda tillståndet
- Ta bort tabelldata baserat på det särskilda tillståndet
- Ta bort alla poster från tabellen
- Släpp bordet
- Släpp databasen
Skapa databasen
Anta att vi måste designa en enkel databas för Library Management System. För att utföra denna uppgift måste en databas skapas i servern som innehåller flera relationstabeller. Efter att ha loggat in på databasservern, kör följande kommando för att skapa en databas med namnet 'bibliotek' i MariaDB-databasservern:
SKAPA DATABAS bibliotek;Utdata visar att biblioteksdatabasen skapas på servern:
 Kör följande kommando för att välja databasen från servern för att utföra olika typer av databasoperationer:
Kör följande kommando för att välja databasen från servern för att utföra olika typer av databasoperationer:
Utdata visar att biblioteksdatabasen är vald:

Skapa tabellerna
Nästa steg är att skapa de nödvändiga tabellerna för databasen att lagra data. Tre tabeller skapas i den här delen av handledningen. Dessa är böcker, medlemmar och borrow_info-tabeller.
- Boktabellen lagrar all bokrelaterad data.
- Medlemstabellen lagrar all information om de medlemmar som lånar boken på biblioteket.
- Tabellen borrow_info lagrar informationen om vilken bok som är lånad av vilken medlem.
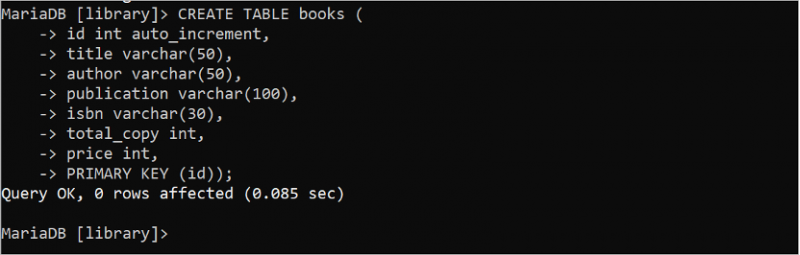
1. Böcker Tabell
Kör följande SQL-sats för att skapa en tabell med namnet 'böcker' i databasen 'bibliotek' som innehåller sju fält och en primärnyckel. Här är 'id'-fältet den primära nyckeln och datatypen är int. Attributet auto_increment används för fältet 'id'. Så värdet på detta fält ökas automatiskt när en ny rad infogas. Varchar-datatypen används för att lagra strängdata för den variabla längden. Fälten för titel, författare, publikation och isbn lagrar strängdata. Datatypen för fälten total_copy och pris är int. Så dessa fält lagrar numeriska data.
SKAPA TABELL böcker (id INT AUTO_INCREMENT ,
titel VARCHAR ( femtio ) ,
författare VARCHAR ( femtio ) ,
offentliggörande VARCHAR ( 100 ) ,
isbn VARCHAR ( 30 ) ,
total_copy INT ,
pris INT ,
PRIMÄR NYCKEL ( id ) ) ;
Resultatet visar att tabellen 'böcker' har skapats framgångsrikt:
2. Medlemmar Tabell
Kör följande SQL-sats för att skapa en tabell med namnet 'medlemmar' i databasen 'bibliotek' som innehåller 5 fält och en primärnyckel. Fältet 'id' har attributet auto_increment som tabellen 'böcker'. Datatypen för de andra fälten är varchar. Så dessa fält lagrar strängdata.
SKAPA TABELL medlemmar (id INT AUTO_INCREMENT ,
namn VARCHAR ( femtio ) ,
adress VARCHAR ( 200 ) ,
kontakt_nr VARCHAR ( femton ) ,
e-post VARCHAR ( femtio ) ,
PRIMÄR NYCKEL ( id ) ) ;
Resultatet visar att tabellen 'medlemmar' har skapats framgångsrikt:

3. Låna_info Tabell
Kör följande SQL-sats för att skapa en tabell med namnet 'borrow_info' i databasen 'library' som innehåller 6 fält. Här är 'id'-fältet primärnyckeln men attributet auto_increment används inte för detta fält. Så ett unikt värde infogas manuellt i detta fält när en ny post infogas i tabellen. Fälten book_id och member_id är främmande nycklar för denna tabell; de är den primära nyckeln i tabellen 'böcker' och tabellen 'medlemmar'. Datatypen för fälten lån_datum och returdatum är datum. Så dessa två fält lagrar datumvärdet i formatet 'ÅÅÅÅ-MM-DD'.
SKAPA TABELL låna_info (id INT ,
låna_datum DATUM ,
bok_id INT ,
member_id INT ,
Återlämningsdatum DATUM ,
STATUS VARCHAR ( 10 ) ,
PRIMÄR NYCKEL ( id ) ,
UTLÄNDSK NYCKEL ( bok_id ) REFERENSER böcker ( id ) ,
UTLÄNDSK NYCKEL ( member_id ) REFERENSER medlemmar ( id ) ) ;
Utdata visar att tabellen 'borrow_info' har skapats framgångsrikt:

Byt namn på tabellnamnet
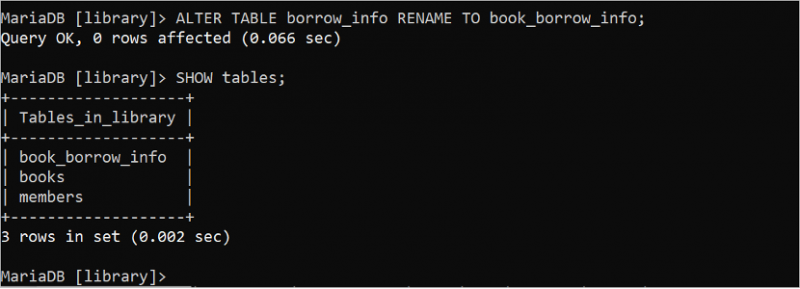
ALTER TABLE-satsen kan användas för flera ändamål i SQL-satserna. Kör följande ALTER TABLE-sats för att ändra namnet på tabellen 'borrow_info' till 'book_borrow_info'. Därefter kan SHOW tables-satsen användas för att kontrollera om namnet på tabellen har ändrats eller inte.
ÄNDRA TABELL låna_info DÖP OM TILL bok_låna_info;SHOW BORD ;
Utdata visar att tabellnamnet har ändrats framgångsrikt och namnet på tabellen borrow_info har ändrats till book_borrow_info:
Lägg till en ny kolumn i tabellen
ALTER TABLE-satsen kan användas för att lägga till eller ta bort en eller flera kolumner efter att tabellen har skapats. Följande ALTER TABLE-sats lägger till ett nytt fält med namnet 'status' till tabellmedlemmarna. DESCRIBE-satsen används för att visa om tabellstrukturen har ändrats eller inte.
ÄNDRA TABELL medlemmar LÄGG TILL STATUS VARCHAR ( 10 ) ;BESKRIVA medlemmar;
Utdata visar att en ny kolumn som är 'status' läggs till i tabellen 'medlemmar' och datatypen för tabellen är varchar:

Ta bort kolumnen från tabellen
Följande ALTER TABLE-sats tar bort fältet med namnet 'status' från tabellen 'medlemmar'. DESCRIBE-satsen används för att visa om tabellstrukturen har ändrats eller inte.
ÄNDRA TABELL medlemmar SLÄPPA KOLUMN STATUS ;BESKRIVA medlemmar;
Utdata visar att kolumnen 'status' har tagits bort från tabellen 'medlemmar':

Infoga en enda rad i tabellen
INSERT INTO-satsen används för att infoga en eller flera rader i tabellen. Kör följande SQL-sats för att infoga en enda rad i tabellen 'böcker'. Här utelämnas 'id'-fältet från denna fråga eftersom det infogas automatiskt i posten när en ny post infogas för auto-increment-attributet. Om detta fält används i INSERT-satsen måste värdet vara NULL.
FÖRA IN IN I böcker ( titel , författare , offentliggörande , isbn , total_copy , pris )VÄRDEN ( 'SQL på 10 minuter' , 'Ben Forta' , 'Sams Publishing' , '784534235' , 5 , 39 ) ;
Utdata visar att en post har lagts till i tabellen 'böcker' framgångsrikt:

Data kan infogas i tabellen med hjälp av SET-satsen där varje fältvärde tilldelas separat. Kör följande SQL-sats för att infoga en enda rad i tabellen 'medlemmar' med hjälp av satserna INSERT INTO och SET. Fältet 'id' utelämnas också i den här frågan som i föregående exempel av samma anledning.
FÖRA IN IN I medlemmarUPPSÄTTNING namn = 'John Sina' , adress = '34, Dhanmondi 9/A, Dhaka' , kontakt_nr = '+14844731336' , e-post = 'john@gmail.com' ;
Utdata visar att en post har lagts till i medlemstabellen framgångsrikt:

Kör följande SQL-sats för att infoga en enda rad i tabellen 'book_borrow_info':
FÖRA IN IN I bok_låna_info ( id , låna_datum , book_id , member_id , Återlämningsdatum , STATUS )VÄRDEN ( 1 , '2023-03-12' , 1 , 1 , '2023-03-19' , 'Lånad' ) ;
Utdata visar att en post läggs till i tabellen 'book_borrow_info':

Infoga flera rader i tabellen
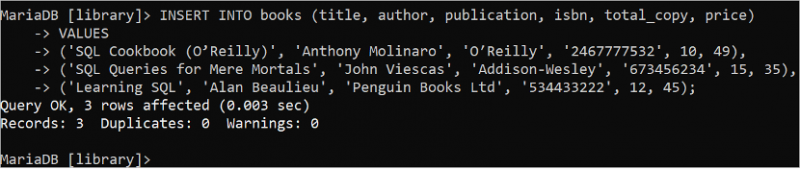
Ibland kräver det att man lägger till många poster samtidigt med en enda INSERT INTO-sats. Kör följande SQL-sats för att infoga tre poster i tabellen 'böcker' med en enda INSERT INTO-sats. I det här fallet används VALUES-satsen en gång och data för varje post separeras med kommatecken.
FÖRA IN IN I böcker ( titel , författare , offentliggörande , isbn , total_copy , pris )VÄRDEN
( 'SQL Cookbook (O'Reilly)' , 'Anthony Molinaro' , 'O'Reilly' , '2467777532' , 10 , 49 ) ,
( 'SQL-frågor för mer dödliga' , 'John Viescas' , 'Addison-Wesley' , '673456234' , femton , 35 ) ,
( 'Lära sig SQL' , 'Alan Beaulieu' , 'Penguin Books Ltd' , '534433222' , 12 , Fyra fem ) ;
Resultatet visar att tre poster läggs till i tabellen 'böcker':
Läs alla särskilda fält från tabellen
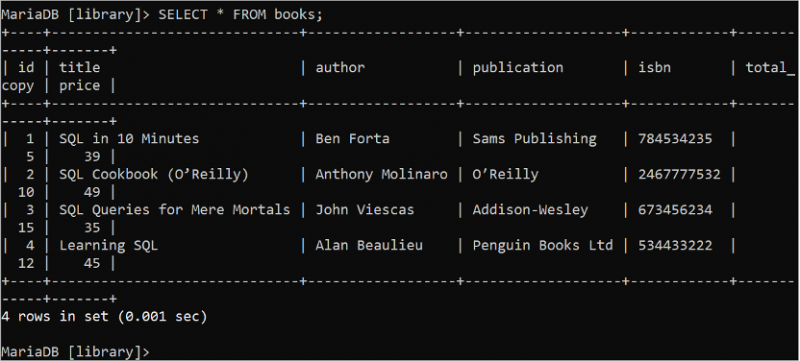
SELECT-satsen används för att läsa data från 'databas'-tabellen. Symbolen '*' används för att beteckna alla fält i tabellen i SELECT-satsen. Kör följande SQL-kommando för att läsa alla poster i boktabellen:
VÄLJ * FRÅN böcker;Utdata visar alla poster i boktabellen som innehåller 4 poster:
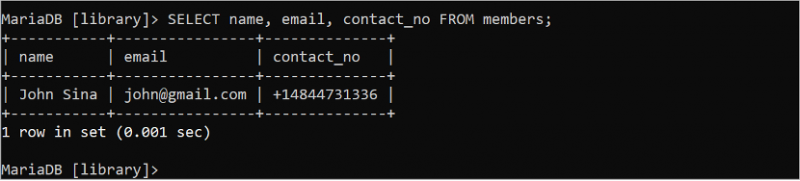
Kör följande SQL-kommando för att läsa alla poster i tre fält i tabellen 'medlemmar':
VÄLJ namn , e-post , kontakt_nr FRÅN medlemmar;Utdata visar alla poster i tre fält i tabellen 'medlemmar':
Läs tabellen efter att ha filtrerat data från tabellen
WHERE-satsen används för att läsa data från en tabell baserat på ett eller flera villkor. Kör följande SELECT-sats för att läsa alla poster i alla fält i tabellen 'böcker' där författarens namn är 'John Viescas'.
VÄLJ * FRÅN böcker VAR författare = 'John Viescas' ;Tabellen 'böcker' innehåller en post som matchar villkoret för WHERE-satsen som visas i utdata:

Läs tabellen efter att ha filtrerat data baserat på boolesk logik
Den booleska AND-logiken används för att definiera flera villkor i WHERE-satsen som returnerar sant om alla villkor returnerar sant. Kör följande SELECT-sats för att läsa alla poster i alla fält i tabellen 'böcker' där värdet på total_copy-fältet är mer än 10 och värdet på prisfältet är mindre än 45 med den logiska OCH.
VÄLJ * FRÅN böcker VAR total_copy > 10 OCH pris < Fyra fem ;Boktabellen innehåller en post som matchar villkoret för WHERE-satsen som visas i utdata:

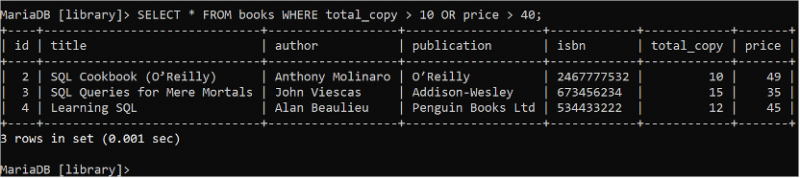
Den booleska ELLER-logiken används för att definiera flera villkor i WHERE-satsen som returnerar sant om något av villkoren returnerar sant. Kör följande SELECT-sats för att läsa alla poster i alla fält i tabellen 'böcker' där värdet på total_copy-fältet är mer än 10 eller värdet på prisfältet är mer än 40.
VÄLJ * FRÅN böcker VAR total_copy > 10 ELLER pris > 40 ;Boktabellen innehåller tre poster som matchar villkoret för WHERE-satsen som visas i utdata:
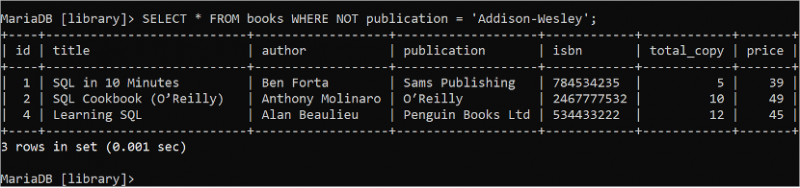
Den booleska NOT-logiken används för att returnera falskt när villkoret är sant och returnerar sant när villkoret är falskt. Kör följande SELECT-sats för att läsa alla poster i alla fält i tabellen 'böcker' där värdet på författarefältet inte är 'Addison-Wesley'.
VÄLJ * FRÅN böcker VAR INTE författare = 'Addison-Wesley' ;Tabellen 'böcker' innehåller tre poster som matchar villkoret för WHERE-satsen som visas i utdata:
Läs tabellen efter att ha filtrerat raderna baserat på dataintervallet
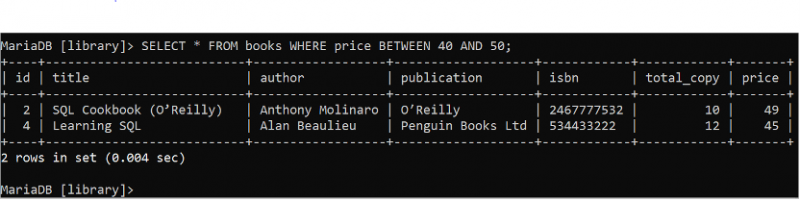
BETWEEN-satsen används för att läsa dataintervallet från databastabellen. Kör följande SELECT-sats för att läsa alla poster i alla fält i tabellen 'böcker' där värdet på prisfältet är mellan 40 och 50.
VÄLJ * FRÅN böcker VAR pris MELLAN 40 OCH femtio ;Boktabellen innehåller två poster som matchar villkoret för WHERE-satsen som visas i utdata. Boken med prisvärdena, 39 och 35, utelämnas från resultatuppsättningen eftersom de ligger utanför intervallet.
Läs tabellen efter att ha sorterat tabellen
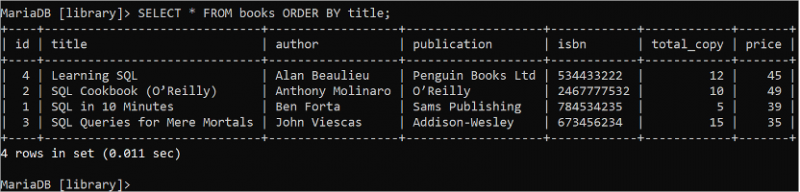
ORDER BY-satsen används för att sortera resultatuppsättningen av SELECT-satsen i stigande eller fallande ordning. Resultatuppsättningen sorteras i stigande ordning som standard om ORDER BY-satsen används utan ASC eller DESC. Följande SELECT-sats läser de sorterade posterna från boktabellen baserat på titelfältet:
VÄLJ * FRÅN böcker BESTÄLLA FÖRBI titel;Data i titelfältet i tabellen 'böcker' sorteras i stigande ordning i utdata. Boken 'Learning SQL' kommer först i alfabetisk ordning om titelfältet i tabellen 'böcker' är sorterat i stigande ordning.
Läs tabellen genom att ställa in det alternativa namnet på kolumnen
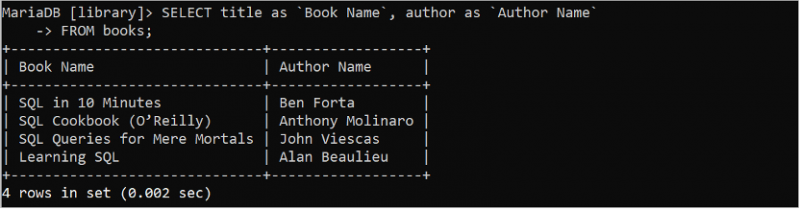
Det alternativa namnet på kolumnen används i frågan för att göra resultatuppsättningen mer läsbar. Det alternativa namnet ställs in med nyckelordet 'AS'. Följande SQL-sats returnerar värdena för titel- och författarefälten genom att ange alternativa namn.
VÄLJ titel SOM 'Bokens namn'. , författare SOM `Författarens namn`FRÅN böcker;
Titelfältet visas med det alternativa namnet som är 'Book Name' och författarens fält visas med det alternativa namnet som är 'Author Name' i utgången.
Räkna det totala antalet rader i tabellen
COUNT() är en aggregerad funktion av SQL som används för att räkna det totala antalet rader baserat på det specifika fältet eller alla fält. Symbolen '*' används för att beteckna alla fält och COUNT(*) används för att räkna alla poster i tabellen.
Följande fråga räknar det totala antalet poster i boktabellen:
VÄLJ RÄKNA ( * ) SOM 'Totalt antal böcker'. FRÅN böcker;Fyra poster i tabellen 'böcker' visas i utdata:

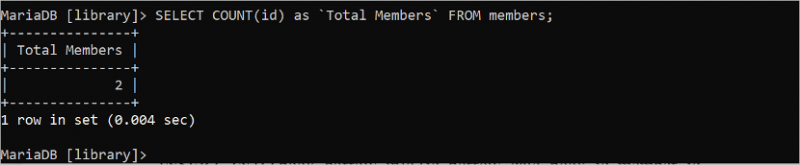
Följande fråga räknar det totala antalet rader i tabellen 'medlemmar' baserat på 'id'-fältet:
VÄLJ RÄKNA ( id ) SOM 'Totalt antal medlemmar'. FRÅN medlemmar;Tabellen 'medlemmar' har två id-värden som skrivs ut i utdata:
Läs data från flera tabeller
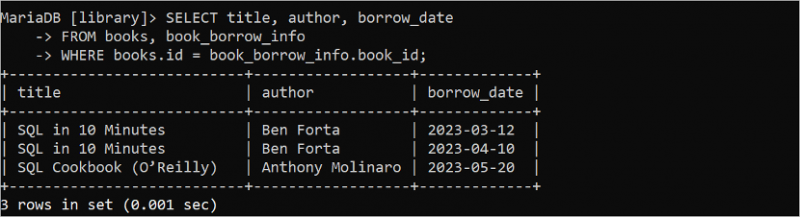
De tidigare SELECT-satserna hämtade data från en enda tabell. Men SELECT-satsen kan användas för att hämta data från två eller flera tabeller. Följande SELECT-fråga läser värdena för titel- och författarefälten från tabellen 'böcker' och lånedatum från tabellen 'boklån_info'.
VÄLJ titel , författare , låna_datumFRÅN böcker , bok_låna_info
VAR böcker . id = bok_låna_info . bok_id;
Följande utdata visar att boken 'SQL på 10 minuter' lånas två gånger och boken 'SQL Cookbook (O'Reilly)' lånas en gång:
Data kan hämtas från flera tabeller med olika typer av JOINS såsom INNER JOIN, OUTER JOIN, etc. som inte förklaras i denna handledning.
Läs tabellen genom att gruppera de särskilda fälten
GROUP BY-satsen används för att läsa posterna från tabellen genom att gruppera raderna baserat på ett eller flera fält. Denna typ av fråga kallas en sammanfattningsfråga. Du måste infoga flera rader i tabellerna för att kontrollera användningen av GROUP BY-satsen. Kör följande INSERT-satser för att infoga en post i tabellen 'members' och två poster i tabellen 'book_borrow_info'.
FÖRA IN IN I medlemmarUPPSÄTTNING namn = 'Hon Hasan' , adress = '11/A, Jigatola, Dhaka' , kontakt_nr = '+8801734563423' , e-post = 'hon@gmail.com' ;
FÖRA IN IN I bok_låna_info ( id , låna_datum , book_id , member_id , Återlämningsdatum , STATUS )
VÄRDEN ( 2 , '2023-04-10' , 1 , 1 , '2023-04-15' , 'Returnerad' ) ;
FÖRA IN IN I bok_låna_info ( id , låna_datum , book_id , member_id , Återlämningsdatum , STATUS )
VÄRDEN ( 3 , '2023-05-20' , 2 , 1 , '2023-05-30' , 'Lånad' ) ;
Efter att ha infogat data genom att köra de föregående frågorna, kör följande SELECT-sats som räknar det totala antalet lånade böcker och medlemmens namn baserat på varje medlem med hjälp av GROUP BY-satsen. Här fungerar COUNT()-funktionen på fältet som används för att omgruppera posterna med hjälp av GROUP BY-satsen. Book_id-fältet i tabellen 'members' används för att gruppera här.
VÄLJ RÄKNA ( book_id ) SOM `Totalt lånad bok` , namn SOM `Medlemsnamn` FRÅN böcker , medlemmar , bok_låna_info VAR böcker . id = bok_låna_info . book_id OCH medlemmar . id = bok_låna_info . member_id GRUPP FÖRBI bok_låna_info . member_id;Enligt uppgifterna i böckerna, 'medlemmar' och 'boklåna_info' lånade 'John Sina' två böcker och 'Ella Hasan' lånade en bok.

Läs tabellen efter att du har utelämnat dubblettvärdena
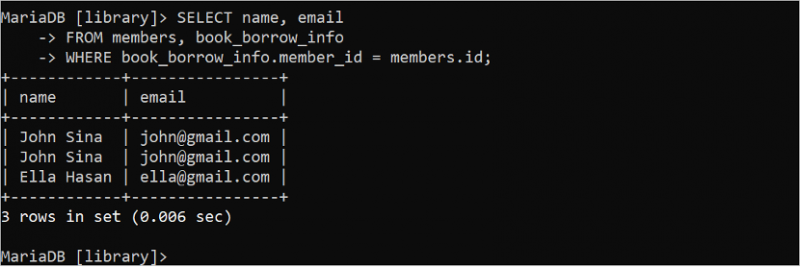
Ibland genereras dubbletter av data i resultatuppsättningen av SELECT-satsen baserat på tabelldata som är onödiga. Till exempel returnerar följande SELECT-sats dubblettposterna för data i tabellen 'book_borrow_info'.
VÄLJ namn , e-postFRÅN medlemmar , bok_låna_info
VAR bok_låna_info . member_id = medlemmar . id;
I utgången visas samma post två gånger eftersom 'John Sina'-medlemmen lånade två böcker. Detta problem kan lösas med nyckelordet DISTINCT. Den tar bort dubblettposterna från frågeresultatet.
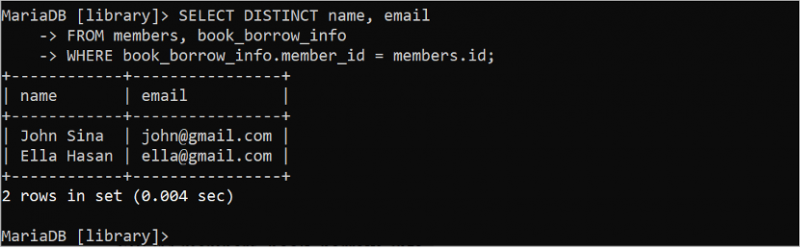
Följande SELECT-sats genererar unika poster för resultatuppsättningen från tabellerna 'members' och 'book_borrow_info' efter att ha utelämnat dubblettvärdena med nyckelordet DISTINCT i frågan.
VÄLJ DISTINKT namn , e-postFRÅN medlemmar , bok_låna_info
VAR bok_låna_info . member_id = medlemmar . id;
Utdata visar att dubblettvärdet tas bort från resultatuppsättningen:
Läs tabellen genom att begränsa radnumret
Ibland kräver det att man läser det specifika antalet poster från början av resultatuppsättningen, slutet av resultatuppsättningen eller mitten av resultatuppsättningen från databastabellen genom att begränsa radnumret. Det kan göras på många sätt. Innan du begränsar raderna, kör följande SQL-sats för att kontrollera hur många poster som finns i boktabellen:
VÄLJ * FRÅN böcker;Resultatet visar att boktabellen har fyra poster:

Följande SELECT-sats läser de två första posterna från 'books'-tabellen med hjälp av LIMIT-satsen med värdet 2:
VÄLJ * FRÅN böcker BEGRÄNSA 2 ;De två första posterna i tabellen 'böcker' hämtas som visas i utdata:

FETCH-satsen är alternativet till LIMIT-satsen och dess användning visas i följande SELECT-sats. De första 3 posterna i tabellen 'böcker' hämtas med hjälp av FETCH FIRST 3 ROWS ONLY-satsen i SELECT-satsen:
VÄLJ * FRÅN böcker HÄMTA FÖRST 3 RADER ENDAST ;Utdata visar de tre första posterna i tabellen 'böcker':

Två rekord från 3:an rd rad i boktabellen hämtas genom att köra följande SELECT-sats. LIMIT-satsen används med 2, 2-värdet här där den första 2 definierar startpositionen för raden i tabellen som börjar räkna från 0 och den andra 2 definierar antalet rader som börjar räknas från startpositionen.
VÄLJ * FRÅN böcker BEGRÄNSA 2 , 2 ;Följande utdata visas efter att föregående fråga har utförts:

Posterna från slutet av tabellen kan läsas genom att sortera tabellen i fallande ordning baserat på det automatiskt inkrementerade primärnyckelvärdet och använda LIMIT-satsen. Kör följande SELECT-sats som läser de två senaste posterna från tabellen 'böcker'. Här sorteras resultatuppsättningen i fallande ordning baserat på 'id'-fältet.
VÄLJ * FRÅN böcker BESTÄLLA FÖRBI id DESC BEGRÄNSA 2 ;De två sista posterna i boktabellen visas i följande utdata:

Läs tabellen baserat på den partiella matchningen
LIKE-satsen används med symbolen '%' för att hämta posterna från tabellen genom partiell matchning. Följande SELECT-sats söker igenom posterna från 'books'-tabellen där författarefältet innehåller 'John' i början av värdet med hjälp av LIKE-satsen. Här används symbolen '%' i slutet av söksträngen.
VÄLJ * FRÅN böcker VAR författare TYCKA OM 'John%' ;Det finns bara en post i tabellen 'böcker' som innehåller 'John'-strängen i början av värdet i författarefältet.

Följande SELECT-sats söker igenom posterna från 'books'-tabellen där publiceringsfältet innehåller 'Ltd' i slutet av värdet med hjälp av LIKE-satsen. Här används symbolen '%' i början av söksträngen:
VÄLJ * FRÅN böcker VAR offentliggörande TYCKA OM '% Ltd' ;Endast en post finns i tabellen 'böcker' som innehåller 'Ltd'-strängen i slutet av publiceringsfältet.

Följande SELECT-sats söker igenom posterna från 'books'-tabellen där titelfältet innehåller 'Queries' var som helst i värdet med hjälp av LIKE-satsen. Här används symbolen '%' på båda sidor om söksträngen:
VÄLJ * FRÅN böcker VAR titel TYCKA OM '%Queries%' ;Endast en post finns i tabellen 'böcker' som innehåller strängen 'Frågor' i titelfältet.

Räkna summan av det särskilda fältet i tabellen
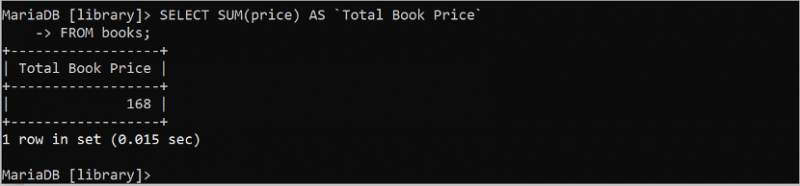
SUM() är en annan användbar aggregatfunktion i SQL som beräknar summan av värdena i alla numeriska fält i tabellen. Denna funktion tar ett argument som måste vara numeriskt. Följande SQL-sats beräknar summan av alla värden i prisfältet i tabellen 'böcker' som innehåller heltalsvärden.
VÄLJ BELOPP ( pris ) SOM `Totalt bokpris`FRÅN böcker;
Utdata visar summavärdet av alla värden i prisfältet i tabellen 'böcker'. Fyra värden i prisfältet är 39, 49, 35 och 45. Summan av dessa värden är 168.
Hitta maximi- och minimivärden för det särskilda fältet
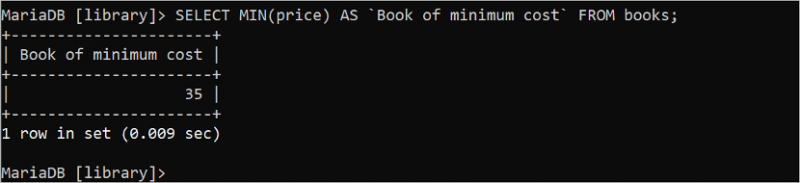
Aggregeringsfunktionerna MIN() och MAX() används för att ta reda på minimi- och maximivärdena för det specifika fältet i tabellen. Båda funktionerna tar ett argument som måste vara numeriskt. Följande SQL-sats tar reda på minimiprisvärdet från tabellen 'böcker', som är ett heltal.
VÄLJ MIN ( pris ) SOM 'Bok med lägsta kostnad'. FRÅN böcker;Trettiofem (35) är minimivärdet för prisfältet som skrivs ut i utdata.
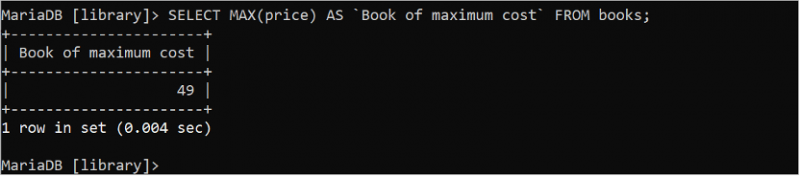
Följande SQL-sats tar reda på det maximala prisvärdet från tabellen 'böcker':
VÄLJ MAX ( pris ) SOM 'Bok med maximal kostnad'. FRÅN böcker;Fyrtionio (49) är det maximala värdet för prisfältet som skrivs ut i utdata.
Läs den särskilda delen av data eller ett fält
Funktionen SUBSTR() används i SQL-satsen för att hämta den särskilda delen av strängdata eller värdet för det specifika fältet i en tabell. Denna funktion innehåller tre argument. Det första argumentet innehåller strängvärdet eller ett fältvärde för en tabell som är en sträng. Det andra argumentet innehåller startpositionen för delsträngen som hämtas från det första argumentet och räkningen av detta värde börjar från 1. Det tredje argumentet innehåller längden på delsträngen som börjar räknas från startpositionen.
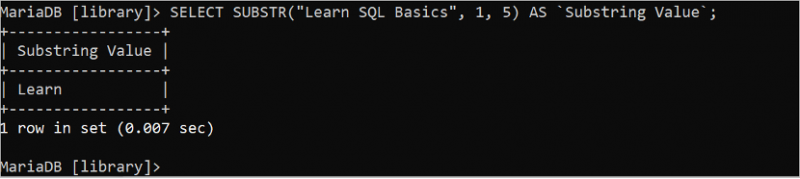
Följande SELECT-sats klipper ut och skriver ut de första fem tecknen från 'Learn SQL Basics'-strängen där startpositionen är 1 och längden är 5:
VÄLJ SUBSTR ( 'Lär dig grunderna i SQL' , 1 , 5 ) SOM 'Substringsvärde'. ;De första fem tecknen i 'Learn SQL Basics'-strängen är 'Learn' som skrivs ut i utgången.
Följande SELECT-sats klipper ut och skriver ut SQL från strängen 'Learn SQL Basics' där startpositionen är 7 och längden är 3:
VÄLJ SUBSTR ( 'Lär dig grunderna i SQL' , 7 , 3 ) SOM 'Substringsvärde'. ;Följande utdata visas efter att föregående fråga har utförts:

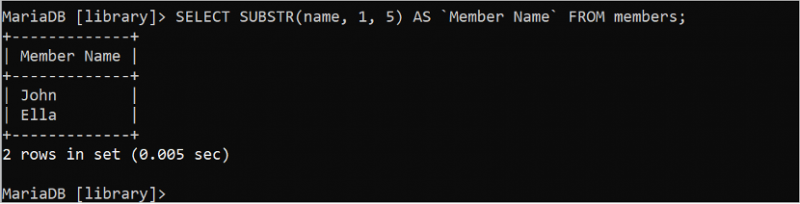
Följande SELECT-sats klipper ut och skriver ut de första fem tecknen från namnfältet i tabellen 'medlemmar':
VÄLJ SUBSTR ( namn , 1 , 5 ) SOM `Medlemsnamn` FRÅN medlemmar;Utdata visar de första fem tecknen i varje värde i namnfältet i tabellen 'medlemmar'.
Läs tabelldata efter sammankoppling
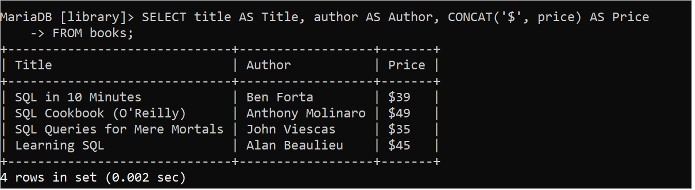
Funktionen CONCAT() används för att generera utdata genom att kombinera ett eller flera fält i en tabell eller lägga till strängdata eller tabellens specifika fältvärde. Följande SQL-sats läser värdena för titel-, författare- och prisfälten i tabellen 'böcker', och strängvärdet '$' läggs till med varje värde i prisfältet med hjälp av CONCAT()-funktionen.
VÄLJ titel SOM Titel , författare SOM Författare , KONCAT ( '$' , pris ) SOM PrisFRÅN böcker;
Värdena i prisfältet skrivs ut i utgången genom att sammanfoga med '$'-strängen.
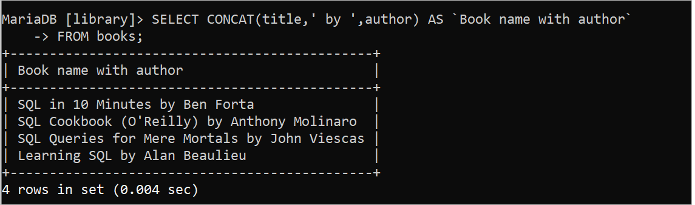
Kör följande SQL-sats för att kombinera värdena för titel- och författarefälten i tabellen 'böcker' med strängvärdet 'by' med hjälp av CONCAT()-funktionen:
VÄLJ KONCAT ( titel , ' förbi ' , författare ) SOM `Boknamn med författare`FRÅN böcker;
Följande utdata visas efter att föregående SELECT-fråga har utförts:
Läs tabelldata efter en matematisk beräkning
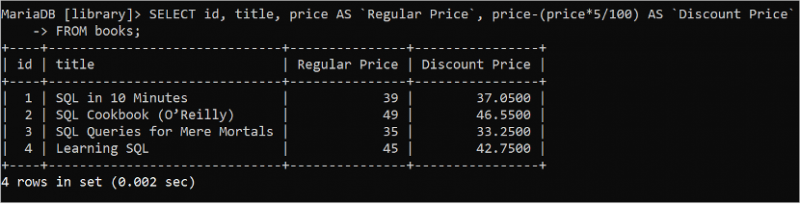
Alla matematiska beräkningar kan utföras vid tidpunkten för hämtning av tabellens värden med hjälp av en SELECT-sats. Kör följande SQL-sats för att läsa id, titel, pris och rabatterat prisvärde efter att ha beräknat rabatten på 5 %.
VÄLJ id , titel , pris SOM 'Ordinarie pris'. , pris - ( pris * 5 / 100 ) SOM `Rabattpris`FRÅN böcker;
Följande utdata visar ordinarie pris och rabattpris för varje bok:
Skapa en vy av tabellen
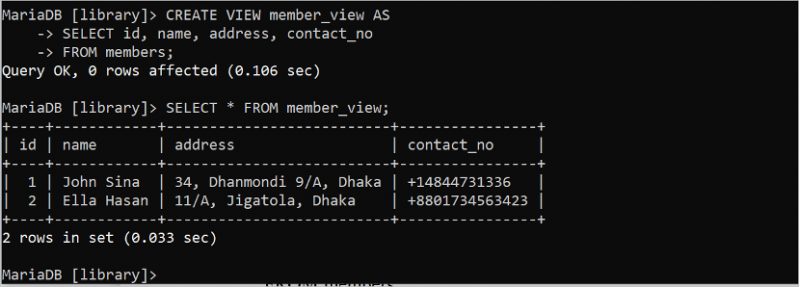
VIEW används för att göra frågan enkel och ger extra säkerhet till databasen. Det fungerar som en virtuell tabell som genereras från en eller flera tabeller. Metoden för att skapa och köra en enkel VIEW baserad på tabellen 'medlemmar' visas i följande exempel. VIEW körs med hjälp av SELECT-satsen. Följande SQL-sats skapar en VIEW av tabellen 'medlemmar' med fälten id, namn, adress och kontakt_nr. SELECT-satsen kör medlemsvyn.
SKAPA SE member_view SOMVÄLJ id , namn , adress , kontakt_nr
FRÅN medlemmar;
VÄLJ * FRÅN member_view;
Följande utdata visas efter att ha skapat och kört vyn:
Uppdatera tabellen baserat på det särskilda tillståndet
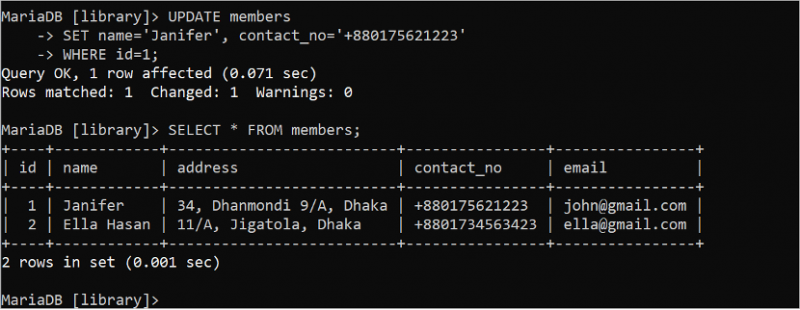
UPDATE-satsen används för att uppdatera innehållet i tabellen. Om någon UPDATE-fråga exekveras utan WHERE-satsen, uppdateras alla fält som används i UPDATE-frågan. Så det är nödvändigt att använda en UPDATE-sats med rätt WHERE-sats. Kör följande UPDATE-sats för att uppdatera fälten namn och kontakt_nr där värdet på id-fältet är 1. Kör sedan SELECT-satsen för att kontrollera om data uppdateras korrekt eller inte.
UPPDATERING medlemmarUPPSÄTTNING namn = 'Janifer' , kontakt_nr = '+880175621223'
VAR id = 1 ;
VÄLJ * FRÅN medlemmar;
Följande utdata visar att UPDATE-satsen exekveras framgångsrikt. Värdet på namnfältet ändras till 'Janifer' och fältet contact_no ändras till '+880175621223' för posten som innehåller id-värdet 1 med UPDATE-frågan:
Ta bort tabelldata baserat på det särskilda tillståndet
DELETE-satsen används för att ta bort det specifika innehållet eller allt innehåll i tabellen. Om någon DELETE-fråga exekveras utan WHERE-satsen raderas alla fält. Så det är nödvändigt att använda UPDATE-satsen med rätt WHERE-sats. Kör följande DELETE-sats för att ta bort all data från boktabellen där id-värdet är 4. Kör sedan SELECT-satsen för att kontrollera om data har raderats korrekt eller inte.
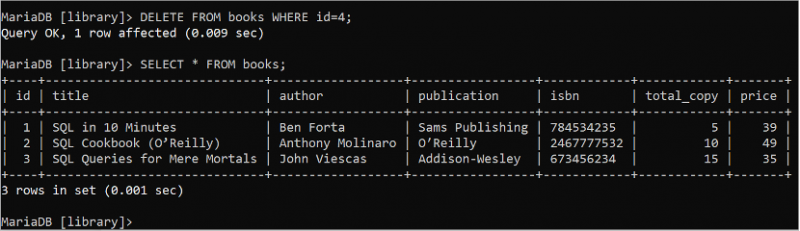
RADERA FRÅN böcker VAR id = 4 ;VÄLJ * FRÅN böcker;
Följande utdata visar att DELETE-satsen exekveras framgångsrikt. Den 4 th posten i boktabellen tas bort med DELETE-frågan:
Ta bort alla poster från tabellen
Kör följande DELETE-sats för att ta bort alla poster från 'books'-tabellen där WHERE-satsen är utelämnad. Kör sedan SELECT-frågan för att kontrollera tabellinnehållet.
RADERA FRÅN book_borrow_info;VÄLJ * FRÅN book_borrow_info;
Följande utdata visar att tabellen 'böcker' är tom efter att ha kört DELETE-frågan:

Om någon tabell innehåller ett attribut för automatisk inkrement och alla poster tas bort från tabellen, börjar fältet för automatisk inkrement att räknas från det sista steget när en ny post infogas efter att tabellen har gjorts tom. Detta problem kan lösas med TRUNCATE-satsen. Den används också för att ta bort alla poster från tabellen men fältet för automatisk ökning börjar räknas från 1 efter att alla poster har tagits bort från tabellen. SQL för TRUNCATE-satsen visas i följande:
STYMPA book_borrow_info;Släpp bordet
En eller flera tabeller kan släppas genom att kontrollera eller utan att kontrollera om tabellen finns eller inte. Följande DROP-satser tar bort tabellen 'book_borrow_info' och satsen 'SHOW tables' kontrollerar om tabellen finns eller inte på servern.
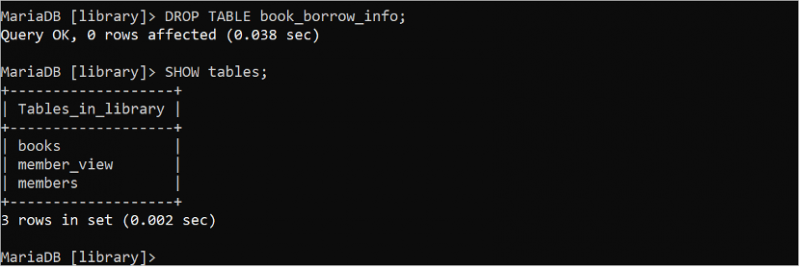
SLÄPPA TABELL bok_låna_info;SHOW BORD ;
Utdata visar att tabellen 'book_borrow_info' tas bort.
Tabellen kan släppas efter att ha kontrollerat om den finns på servern eller inte. Kör följande DROP-sats för att ta bort bok- och medlemstabellen om dessa tabeller finns på servern. Därefter kontrollerar 'SHOW tables'-satsen om tabellerna finns eller inte på servern.
SLÄPPA TABELL OM EXISTERAR böcker , medlemmar;SHOW BORD ;
Följande utdata visar att tabellerna raderas från servern:

Släpp databasen
Kör följande SQL-sats för att ta bort 'bibliotek'-databasen från servern:
SLÄPPA DATABAS bibliotek;Utdata visar att databasen har tappats.

Slutsats
De mest använda SQL-frågeexemplen för att skapa, komma åt, ändra och ta bort databasen för MariaDB-servern visas i denna handledning genom att skapa en databas och tre tabeller. Användningen av olika SQL-satser förklaras med mycket enkla exempel för att hjälpa den nya databasanvändaren att lära sig grunderna i SQL ordentligt. Användningen av komplexa frågor utelämnas här. De nya databasanvändarna kommer att kunna börja arbeta med vilken databas som helst efter att ha läst den här handledningen ordentligt.