Dalle-mini är en modell för djupinlärning som kan generera bilder av hög kvalitet från användarinmatad text. Den är baserad på DALL-E-modellen, som OpenAI släppte i januari 2021. DALL-E står för “ Disentangled språk och latent uttryck ” är ett transformatorbaserat neuralt nätverk som kan koda text och bilder till ett gemensamt latent utrymme och sedan avkoda dem tillbaka till endera modaliteten.
Den här artikeln kommer att förklara följande innehåll:
Vad är Dalle-mini?
Ge henne-mini är en mindre och snabbare version av DALL-E, som skapades av EleutherAI, ett forskningskollektiv med öppen källkod. Dalle-mini använder bara 6 miljarder parametrar, jämfört med DALL-E:s 12 miljarder, och den kan köras på en enda GPU. Dalle-mini använder också en annan tokenizer och ordförråd för textinmatningen, vilket gör den mer kompatibel med olika språk och domäner:

Notera : Användare kan skapa kostnadsfria bilder med hjälp av Dalle-mini genom att följa länk .
Hur fungerar Dalle-mini?
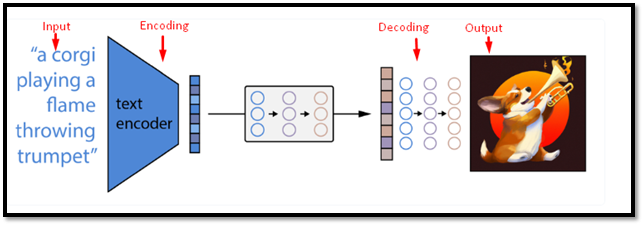
Huvudtanken bakom Dalle-mini är kraften hos transformatorer, som är neurala nätverk. De kan lära sig långväga beroenden och komplexa mönster i sekventiell data, som text eller bilder.
Transformatorer består av två huvuddelar: en kodare och en avkodare. Den första delen tar en ingång (en textbeskrivning) och ändrar den till dolda vektorer. Efter det tar avkodaren det och genererar en utdata (en bild) som är relevant för ingången.
Vad är skillnaden mellan Dalle-mini och DALL-E?
Dalle-mini och DALL-E använder en delad encoder-decoder-arkitektur för både text och bilder. De kan koda och avkoda båda modaliteterna med samma nätverk. Detta gör att de kan lära sig ett gemensamt latent utrymme som fångar det semantiska förhållandet mellan text och bilder. Efter det, gör det möjligt för dem att utföra cross-modal generation, som att skapa bilder från text eller vice versa.
Hur fungerar Dalle-mini?
För att generera en bild från en textbeskrivning, tokeniserar Dalle-mini först texten med hjälp av en byte-pair encoding (BPE) algoritm, som delar upp texten i underordsenheter baserat på deras frekvens och samtidig förekomst:
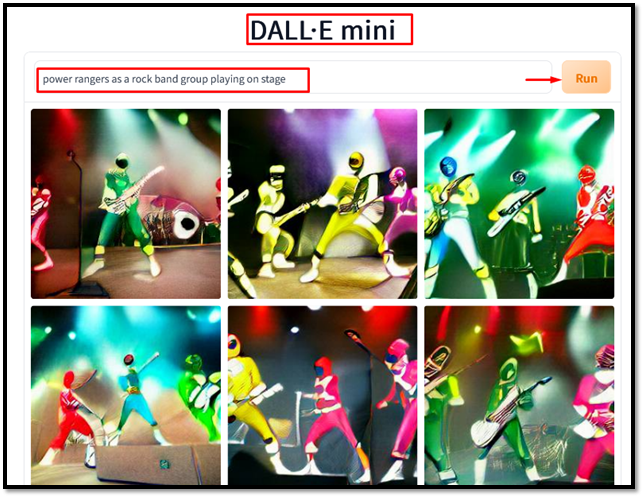
Låt oss gå in på detaljerad intern drift av Dalle-mini:
Internt arbete i Dalle-mini
Låt oss anta att ordet ' spelar ' kan delas upp i ' pla ' och ' ying ”. Polletterna mappas sedan till numeriska ID:n med hjälp av ett ordförråd på 8192 tokens. ID:n matas in i kodaren, vilket ger en latent representation av storleken 256 x 64:
Avkodaren tar sedan den latenta representationen och genererar en bild med storleken 256 x 256 pixlar. Avkodaren använder en autoregressiv process, vilket innebär att den genererar varje pixel en efter en, beroende på de föregående pixlarna och den latenta representationen.
Hur man genererar bild från textbeskrivning med Dalle-mini?
För att skapa en textbeskrivning från en bild med hjälp av Dalle-mini, skriv in texten i promptfönstret. Skriv till exempel ' En målning av slumpmässiga blommor ' i prompten och tryck på ' Springa ' knapp:
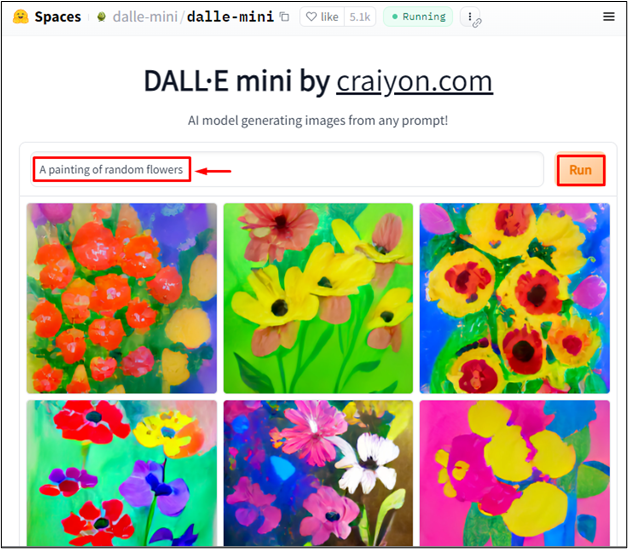
Resultatet visar att Dalle-mini har genererat relevanta bilder enligt inmatningstexten.
Slutsats
Dalle-mini är en anmärkningsvärd modell som visar transformatorernas potential för cross-modal generation. De kan skapa realistiska och mångsidiga bilder från naturliga språkbeskrivningar, såväl som sammanhängande och relevanta texter från bilder. De kan också hantera komplexa kompositioner, som att kombinera flera objekt eller attribut i en bild eller text. Den här artikeln har förklarat Dalle-mini och dess funktion i detalj.