Elasticsearch är en robust, omtyckt lösning för att lagra skrymmande, ostrukturerad och semi-strukturell data. Det är en ren NoSQL-databas och använder ett helt annat tillvägagångssätt för att lagra, hantera och hämta data. Den lagrar data i ett dokument i JSON-format och använder vilo-API:er för att utföra olika operationer på lagrad data.
I den här bloggen kommer vi att visa:
- Hur Elasticsearch fungerar för att lagra och söka efter data?
- Vad är Elasticsearch-dokument?
- Hur lagrar man data i ett Elasticsearch-dokument?
Hur Elasticsearch fungerar för att lagra och söka efter data?
Elasticsearchs huvudkomponenter eller hierarki som används för att lagra data listas nedan:
- Dokumentera: Dokumentet är huvuddelen av Elasticsearch som lagrar data i JSON-format. Tycka om
- Index: Index kallas för index. Det är en samling dokument. Liksom i SQL kallas det en databas.
- Inverterade index: Den stöder mycket snabb fulltextsökning. Den lagrar ordet som ett index och namnet på dokumentet som referens.
Vad är Elasticsearch-dokument?
Elasticsearch-dokumentet är en lagringsenhet av data i JSON-format. Liksom i relationsdatabaser kan dokumentet refereras till som en tabell eller en rad i en databas som lagras i något index. Indexet kan ha flera dokument och kallas en databas som har flera tabeller. Den lagrar vanligtvis en komplex datastruktur och steriliserar data i JSON-format.
Dessutom kan varje dokument innehålla flera fält som är ' nyckelvärde ” parar för att lagra data precis som en tabell har flera kolumner eller fält i en relationsdatabas. Sedan är dessa nyckel-värdepar tänkta att indexeras på ett sätt för att fastställa dokumentmappningen. Mappningen definierar sedan dokumentets datatyp enligt fältdata som text, flytande, geopunkt, tid och många fler.
Elasticsearch binder oss aldrig till att fördefiniera indexfältstrukturen och dokumenten kan ha olika fältstruktur i ett index. Men om mappningen av fältet är definierad för en specifik datatyp måste alla Elasticsearch-dokument i ett index följa samma mappningstyp. För att kolla in hur dokumentet fungerar för att lagra data i Elasticsearch, gå igenom nästa avsnitt.
Hur lagrar man data i ett Elasticsearch-dokument?
För att lagra data i Elasticsearch måste användaren först skapa ett index. Ange sedan fälten för att lagra data i Elasticsearch-dokumentet. För demonstrationen, gå igenom de listade stegen.
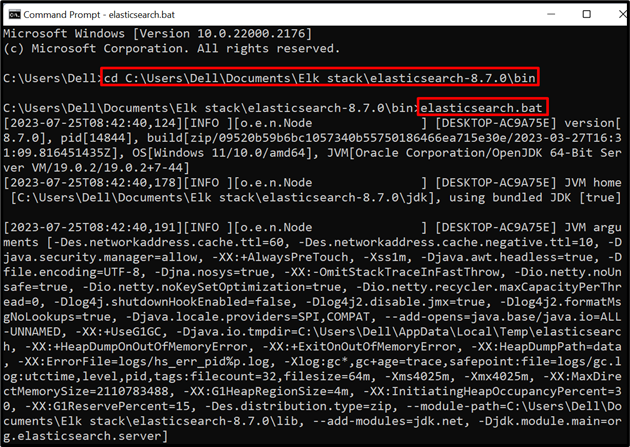
Steg 1: Starta Elasticsearch
För att köra Elasticsearch-databasen eller motorn på systemet, starta systemterminalen som kommandotolken. Efter det, besök ' bin '-mappen för Elasticsearch genom ' CD ” kommando:
CD C:\Users\Dell\Documents\Elk stack\elasticsearch-8.7.0\bin
Efter det, kör batchfilen för Elasticsearch för att köra databasen på systemet:
elasticsearch.bat
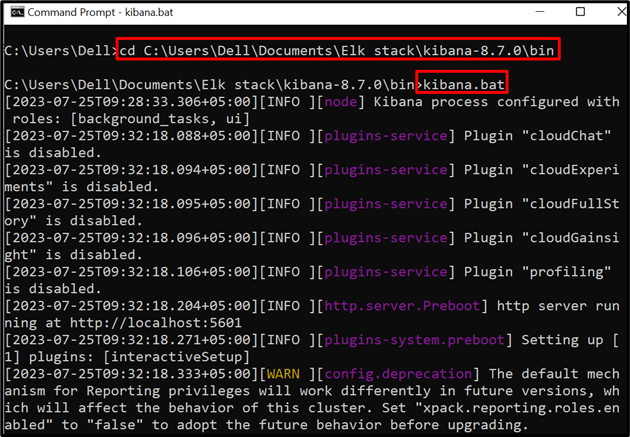
Steg 2: Starta Kibana
Kör sedan Kibana på systemet. För att göra det, besök dess ' bin ' mapp från kommandotolken:
CD C:\Users\Dell\Documents\Elk stack\kibana-8.7.0\bin
Kör sedan kommandot nedan för att börja köra Kibana:
kibana.bat
Notera: Om du inte har installerat och ställt in Elasticsearch och Kibana på systemet, navigera till våra inlägg och kolla in steg-för-steg-proceduren för att installera dem på systemet.
För Elasticsearch, besök vår ' Installera och konfigurera Elasticsearch med .zip på Windows ' artikel. För att ställa in Kibana på Windows, följ ' Ställ in Kibana för Elasticsearch ' artikel.
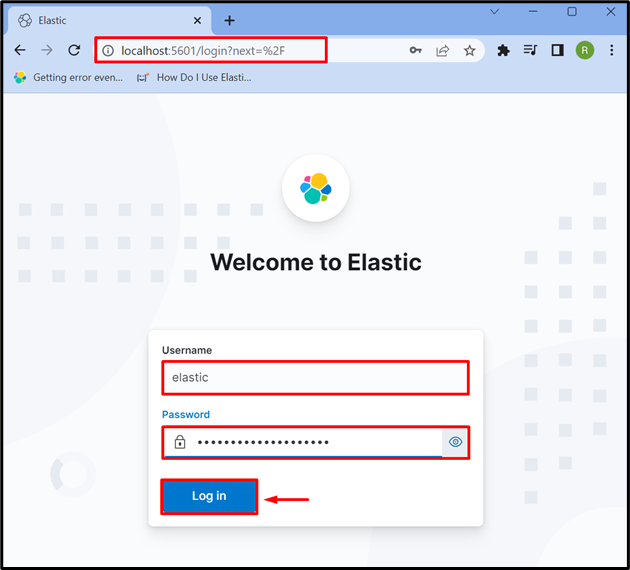
Steg 3: Logga in på Kibana
Efter att ha startat Kibana på systemet, navigera till standardadressen för Kibana ' lokal värd: 5601 ” i webbläsaren och ange inloggningsuppgifterna för Elasticsearch som ” elastisk ” användare och lösenord. Efter det, tryck på ' Logga in ' knapp:
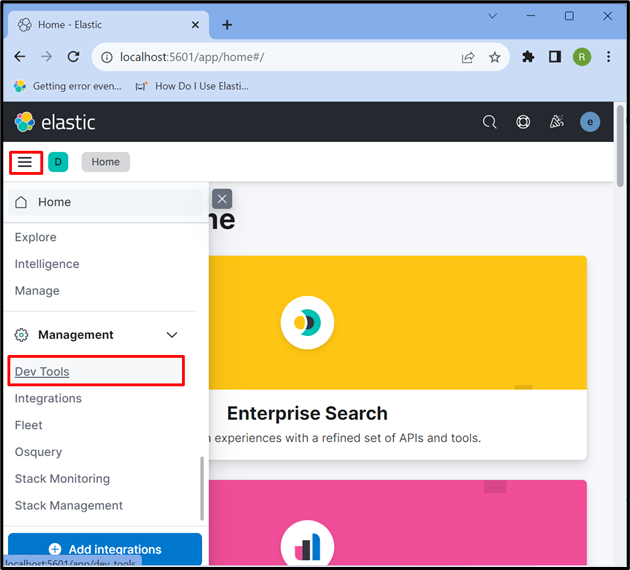
Steg 4: Öppna Kibana 'Dev Tool'
Efter det klickar du på ' Tre horisontella staplar ' ikonen och öppna Kibana ' Dev Tool ” för att använda API:er för att lagra, hämta och uppdatera data:
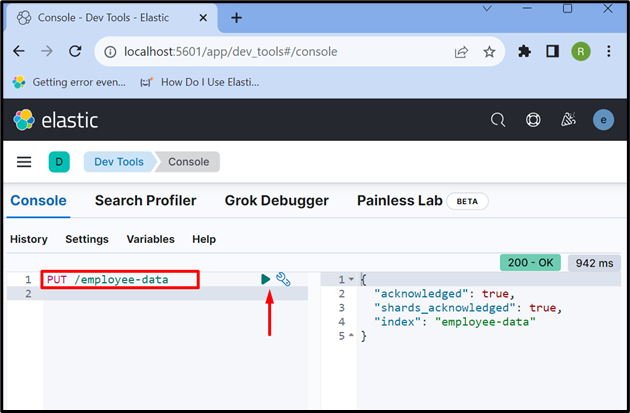
Steg 5: Skapa index
Skapa nu ett nytt index med ' PUT /
Utdata visar att ' anställd-data ” index har skapats framgångsrikt:
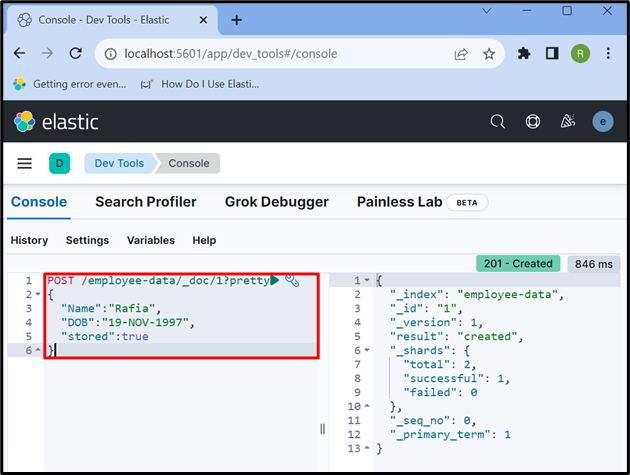
Steg 6: Infoga data i dokument
Använd nu ' POSTA ” API för att lagra data i indexet. I begäran nedan, ' anställd-data ' är ett index för Elasticsearch, ' _doc ' används för att lagra data i Elasticsearch-dokument, och ' 1 ” är id:t:
POSTA / anställd-data / _doc / 1 ?Söt{
'Namn' : 'Bast' ,
'DOB' : '19-NOV-1997' ,
'lagrad' :Sann
}
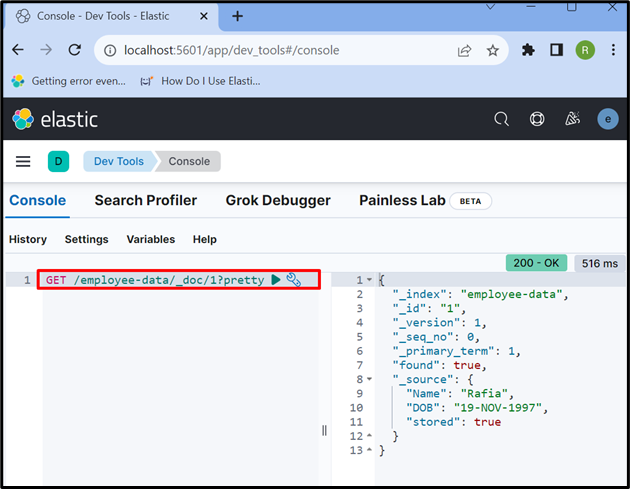
Steg 7: Hämta data från Elasticsearch-dokument
För att komma åt data från indexet eller Elasticsearch-dokumentet, använd ' SKAFFA SIG ' API som används nedan:
SKAFFA SIG / anställd-data / _doc / 1 ?Söt
Resultatet visar att vi framgångsrikt har extraherat data från Elasticsearch-dokumentet med id ' 1 ”:
Det handlar om Elasticsearch-dokumentet.
Slutsats
Elasticsearch-dokumentet används vanligtvis för att lagra data i JSON-format. Liksom i relationsdatabaser kan dokumentet refereras till som en rad som lagras i något index. Dessa index kan ha flera dokument precis som databaser har olika tabeller. Dessa dokument innehåller flera fält som är ' nyckelvärde ” parar för att lagra data. Den här artikeln har visat vad Elasticsearch-dokument är och hur de fungerar i Elasticsearch.