Multiprocessing är jämförbar med multithreading. Det skiljer sig dock på att vi bara kan köra en tråd åt gången på grund av GIL som används för trådning. Multiprocessing är processen att utföra operationer sekventiellt över flera CPU-kärnor. Trådar kan inte användas parallellt. Men multiprocessing tillåter oss att etablera processerna och köra dem samtidigt på olika CPU-kärnor. Slingan, såsom for-loopen, är ett av de mest använda skriptspråken. Upprepa samma arbete med olika data tills ett kriterium, såsom ett förutbestämt antal iterationer, uppnås. Slingan utför varje iteration en efter en.
Exempel 1: Använda For-Loop i Python Multiprocessing Module
I det här exemplet använder vi klassprocessen for-loop och Python multiprocessing modul. Vi börjar med ett mycket enkelt exempel så att du snabbt kan förstå hur Python multiprocessing for-loop fungerar. Genom att använda ett gränssnitt som är jämförbart med gängningsmodulen, packar multiprocessen skapandet av processer.
Genom att använda delprocesserna snarare än trådar, tillhandahåller multiprocessing-paketet både lokal och avlägsen samtidighet, vilket undviker Global Interpreter Lock. Använd en for-loop, som kan vara ett strängobjekt eller en tuppel, för att kontinuerligt iterera genom en sekvens. Detta fungerar mindre som nyckelordet i andra programmeringsspråk och mer som en iteratormetod som finns i andra programmeringsspråk. Genom att starta en ny multiprocessing kan du köra en for-loop som exekverar en procedur samtidigt.
Låt oss börja med att implementera koden för kodexekvering genom att använda verktyget 'spyder'. Vi tror att 'spyder' också är det bästa för att köra Python. Vi importerar en multiprocessing modul process som koden körs. Multiprocessing i Python-konceptet som kallas en 'process class' skapar en ny Python-process, ger den en metod för att exekvera kod och ger den överordnade applikationen ett sätt att hantera exekveringen. Klassen Process innehåller procedurerna start() och join(), som båda är avgörande.
Därefter definierar vi en användardefinierad funktion som kallas 'func'. Eftersom det är en användardefinierad funktion ger vi den ett valfritt namn. Inuti kroppen av den här funktionen skickar vi 'subject'-variabeln som ett argument och 'matte'-värdet. Därefter anropar vi 'print()'-funktionen och skickar påståendet 'Namnet på det gemensamma ämnet är' såväl som dess 'subject'-argument som innehåller värdet. Sedan, i följande steg, använder vi 'if name== _main_', som hindrar dig från att köra koden när filen importeras som en modul och endast tillåter dig att göra det när innehållet körs som ett skript.
Villkorsavsnittet du börjar med kan i de flesta fall ses som en plats för att tillhandahålla innehållet som endast bör köras när din fil körs som ett skript. Sedan använder vi argumentet ämne och lagrar några värden i det som är 'vetenskap', 'engelska' och 'dator'. Processen får sedan namnet 'process1[]' i följande steg. Sedan använder vi 'process(target=func)' för att anropa funktionen i processen. Target används för att anropa funktionen, och vi sparar denna process i variabeln 'P'.
Därefter använder vi 'process1' för att anropa funktionen 'append()' som lägger till ett objekt i slutet av listan som vi har i funktionen 'func.' Eftersom processen är lagrad i variabeln 'P', skickar vi 'P' till denna funktion som dess argument. Slutligen använder vi funktionen 'start()' med 'P' för att starta processen. Efter det kör vi metoden igen samtidigt som vi tillhandahåller argumentet 'subject' och använder 'för' i ämnet. Sedan, med hjälp av 'process1' och 'add()'-metoden en gång till, börjar vi processen. Processen körs sedan och utgången returneras. Proceduren uppmanas sedan att avslutas med 'join()'-tekniken. De processer som inte anropar 'join()'-proceduren kommer inte att avslutas. En avgörande punkt är att nyckelordsparametern 'args' måste användas om du vill ge några argument genom processen.
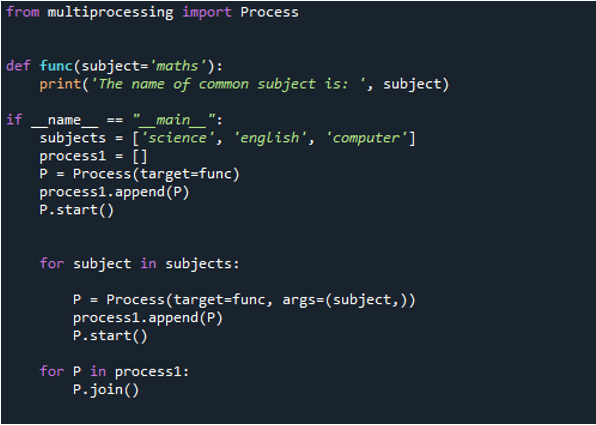
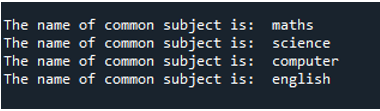
Nu kan du se i utgången att satsen visas först genom att skicka värdet för 'matematik'-ämnet som vi skickar till 'func'-funktionen eftersom vi först kallar det med 'process'-funktionen. Sedan använder vi kommandot 'append()' för att ha värden som redan fanns i listan som läggs till i slutet. Sedan presenterades 'vetenskap', 'dator' och 'engelska'. Men, som du kan se, är värdena inte i rätt ordning. Det beror på att de gör det så fort som proceduren är klar och rapporterar sitt meddelande.
Exempel 2: Konvertering av sekventiell For-Loop till Multiprocessing Parallel For-Loop
I det här exemplet exekveras multiprocessing loop-uppgiften sekventiellt innan den konverteras till en parallell for-loop-uppgift. Du kan bläddra igenom sekvenser som en samling eller sträng i den ordning de inträffar med hjälp av for-looparna.
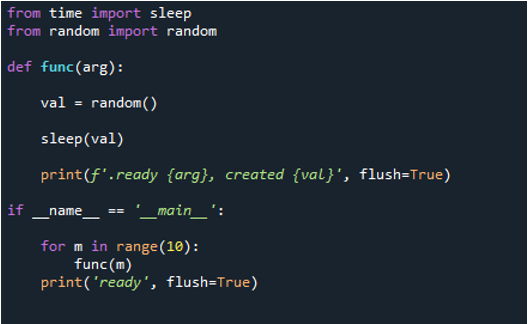
Låt oss nu börja implementera koden. Först importerar vi 'sömn' från tidsmodulen. Genom att använda 'sleep()'-proceduren i tidsmodulen kan du avbryta exekveringen av den anropande tråden så länge du vill. Sedan använder vi 'random' från slumpmodulen, definierar en funktion med namnet 'func' och skickar nyckelordet 'argu'. Sedan skapar vi ett slumpmässigt värde med 'val' och ställer in det på 'slumpmässigt'. Sedan blockerar vi en liten period med metoden 'sleep()' och skickar 'val' som en parameter. Sedan, för att överföra ett meddelande, kör vi metoden 'print()' och skickar orden 'ready' och nyckelordet 'arg' som parameter, samt 'created' och skickar värdet med 'val'.
Slutligen använder vi 'flush' och ställer in den på 'True'. Användaren kan bestämma om utdata ska buffras eller inte med hjälp av flush-alternativet i utskriftsfunktionen i Python. Den här parameterns standardvärde på False indikerar att utdata inte kommer att buffras. Utdata visas som en serie rader efter varandra om du ställer in den på sann. Sedan använder vi 'if name== main' för att säkra ingångspunkterna. Därefter utför vi jobbet sekventiellt. Här sätter vi intervallet till '10' vilket betyder att slingan slutar efter 10 iterationer. Därefter anropar vi funktionen 'print()', skickar den inmatningssatsen 'ready' och använder alternativet 'flush=True'.
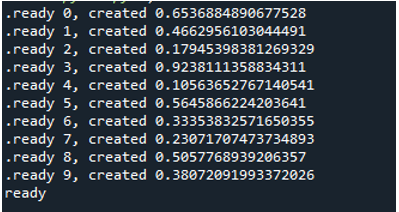
Du kan nu se att när vi exekverar koden gör loopen att funktionen körs '10' gånger. Den itererar genom 10 gånger, börjar vid index noll och slutar vid index nio. Varje meddelande innehåller ett uppgiftsnummer som är ett funktionsnummer som vi skickar in som ett 'arg' och ett skapande nummer.
Denna sekventiella loop omvandlas nu till en parallell för-loop för flera bearbetning. Vi använder samma kod, men vi ska till några extra bibliotek och funktioner för multiprocessing. Därför måste vi importera processen från multiprocessing, precis som vi förklarade tidigare. Därefter skapar vi en funktion som heter 'func' och skickar nyckelordet 'arg' innan vi använder 'val=random' för att få ett slumptal.
Sedan, efter att ha anropat 'print()'-metoden för att visa ett meddelande och ge parametern 'val' för att fördröja en liten period, använder vi funktionen 'if name= main' för att säkra ingångspunkterna. Därefter skapar vi en process och anropar funktionen i processen med hjälp av 'process' och skickar 'target=func'. Sedan skickar vi 'func', 'arg', skickar värdet 'm' och passerar intervallet '10' vilket betyder att slingan avslutar funktionen efter '10' iterationer. Sedan startar vi processen med 'start()'-metoden med 'process'. Sedan anropar vi metoden 'join()' för att vänta på exekveringen av processen och för att slutföra hela processen efter.
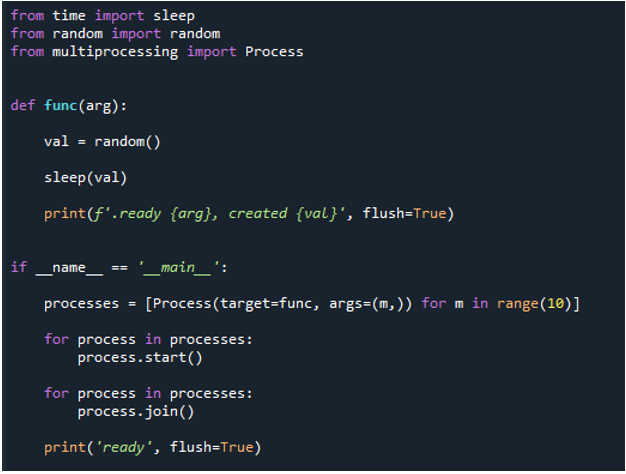
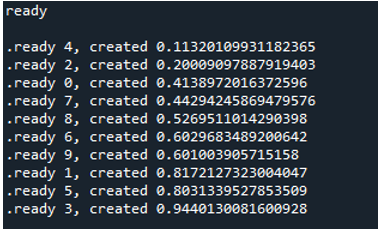
Därför, när vi exekverar koden, anropar funktionerna huvudprocessen och påbörjar sin exekvering. De görs dock tills alla uppgifter är klara. Vi kan se det eftersom varje uppgift utförs samtidigt. Den rapporterar sitt meddelande så snart det är klart. Detta innebär att även om meddelandena är ur funktion, slutar loopen efter att alla '10' iterationer har slutförts.
Slutsats
Vi täckte Python multiprocessing for-loop i den här artikeln. Vi presenterade också två illustrationer. Den första illustrationen visar hur man använder en for-loop i Pythons loop-multiprocessing-bibliotek. Och den andra illustrationen visar hur man ändrar en sekventiell for-loop till en parallell multiprocessing for-loop. Innan vi konstruerar skriptet för Python multiprocessing måste vi importera multiprocessing modulen.