Som databasadministratörer måste vi vara besatta av verktygen och metoderna för att förbättra databasens prestanda.
I PostgreSQL har vi tillgång till kommandot EXPLAIN ANALYZE som låter oss analysera exekveringsplanen och prestandan för en given databasfråga. Kommandot returnerar en detaljerad information om hur databasmotorn bearbetar frågan. Detta inkluderar sekvensen av utförda operationer, uppskattade frågekostnader, exekveringstid och mer.
Vi kan sedan använda denna information för att identifiera databasfrågorna samt identifiera och åtgärda potentiella prestandaflaskhalsar.
Denna handledning diskuterar hur man använder kommandot EXPLAIN ANALYZE i PostgreSQL för att visa och optimera frågeprestanda.
PostgreSQL FÖRKLARA ANALYSE
Kommandot är ganska enkelt. Först måste vi lägga till kommandot EXPLAIN ANALYZE i början av frågan som vi vill analysera.
Kommandosyntaxen är som följer:
FÖRKLARA ANALYSENär du väl kört kommandot returnerar PostgreSQL en detaljerad utdata om den angivna frågan.
Förstå EXPLAIN ANALYSE Query Output
Som nämnts, när vi kör kommandot EXPLAIN ANALYZE, genererar PostgreSQL en detaljerad rapport över frågeplanen och exekveringsstatistiken.
Resultatet består av en uppsättning kolumner som innehåller användbar information. De resulterande kolumnerna är som visas med sina respektive betydelser:
FÖRFRÅGEPLAN – Den här kolumnen visar exekveringsplanen för den angivna frågan. Exekveringsplanen hänvisar till en sekvens av operationer som databasmotorn utför för att slutföra frågan framgångsrikt.
PLANEN – Den andra kolumnen är PLAN-kolumnen. Denna innehåller en textuell representation av varje operation eller steg i utförandeplanen. Återigen är varje operation indragen för att indikera operationshierarkin.
TOTAL KOSTNAD – Kolumnen för totalkostnad representerar den uppskattade totala kostnaden för frågan. Kostnaden avser ett relativt mått som databasfrågeplaneraren använder för att bestämma den optimala exekveringsplanen.
VERKLIGA RADER – Den här kolumnen visar det exakta antalet rader som bearbetas vid varje steg i frågekörningen.
VERKLIG TID – Den här kolumnen visar den faktiska tiden som varje operation tar, vilket inkluderar både utförandetiden för operationen och tiden som spenderas på resurser.
PLANERINGSTID – Den här kolumnen visar den tid det tar för frågeplaneraren att generera en exekveringsplan. Detta inkluderar den totala tiden för frågeoptimeringen och plangenereringen.
UTFÖRANDETID – Den här kolumnen visar den totala tiden för att köra frågan. Detta inkluderar också den tid som läggs på planering och utförande av frågor.
PostgreSQL EXPLAIN ANALYS Exempel
Låt oss titta på några grundläggande exempel på hur man använder EXPLAIN ANALYZE-satsen.
Exempel 1: Välj Utlåtande
Låt oss använda EXPLAIN ANALYZE-satsen för att visa exekveringen av en enkel select-sats i PostgreSQL.
När vi kört den föregående satsen bör vi få en utdata enligt följande:
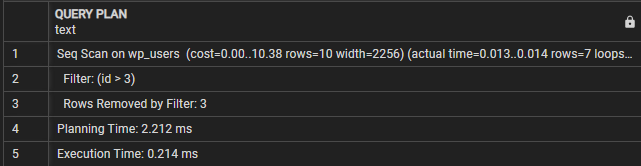
FÖRFRÅGEPLAN-------------------------------------------------- ------------------
Seq Scan on wp_users (kostnad=0.00..10.38 rader=10 bredd=2256) (faktisk tid=0.009..0.010 rader=7 loopar=1)
Filter: (id > 3)
Rader borttagna med filter: 3
Planeringstid: 0,995 ms
Utförandetid: 0,021 ms
(5 rader)
I det här fallet kan vi se att avsnittet Frågeplan indikerar att frågan utför en sekventiell genomsökning av tabellen wp_users. Filterraden anger villkoret som används för att filtrera de resulterande raderna.
Vi ser sedan 'Rader borttagna av filter' som visar antalet rader som elimineras av filtervillkoret.
Slutligen visar exekveringstiden den totala exekveringstiden för frågan. I det här fallet tar frågan 0,021ms.
Exempel 2: Analysera en Join
Låt oss ta en mer komplex fråga som involverar en SQL-join. För detta använder vi Pagilas exempeldatabas. Du kan ladda ner och installera exempeldatabasen på din maskin för demonstrationsändamål.
Vi kan köra en enkel join som visas i följande:
förklara analysera VÄLJ f.titel, c.namnFRÅN film f
JOIN film_category fc PÅ f.film_id = fc.film_id
JOIN kategori c PÅ fc.category_id = c.category_id;
När vi har kört den givna frågan bör vi se resultatet enligt följande:
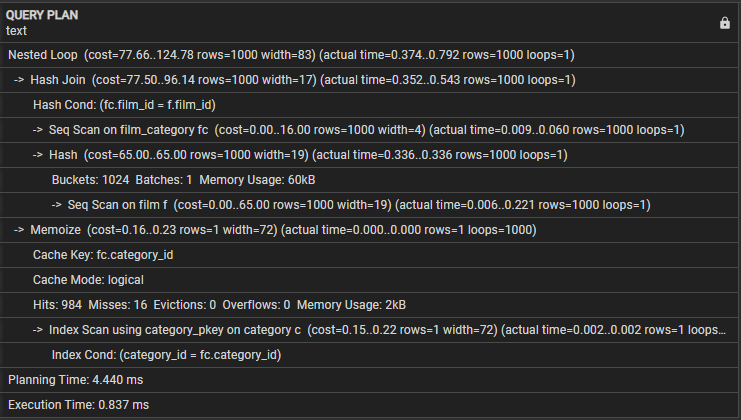
Låt oss utforska följande frågeplan:
- Kapslad loop – Detta indikerar att sammanfogningen använder en kapslad loop-anslutningsstrategi.
- Hash Join – Denna operation förenar filmkategorin och filmtabellerna med hjälp av en Hash Join-algoritm. Denna operation har en kostnad på 77,50 och beräknas 1000 rader. Den faktiska tiden det tar för denna operation är dock 0,254 till 0,439 millisekunder, och den hämtar 1000 rader.
- Hash Cond – Detta indikerar att joinvillkoret använder en Hash-join för att matcha film_id-kolumnerna och film_category-kolumnerna i filmtabellerna.
- Seq Scan on film_category – Denna operation utför en sekventiell skanning av tabellen film_category med en kostnad på 16,00 och beräknad 1000 rader. Den faktiska tiden det tar för denna operation är 0,008 till 0,056 millisekunder, och den hämtar 1000 rader.
- Seq Scan on film – Frågan utför en sekventiell skanning av filmtabellen med resulterande uppskattade och faktiska kostnader och rader i denna operation.
- Memoize – Den här operationen cachelagrar resultaten av kopplingen mellan film_category och filmtabeller för senare användning.
- Cache-nyckel – Detta indikerar att cache-nyckeln som används för memoisering är baserad på kategori_id-kolumnen från film_category.
- Cacheläge – Detta indikerar att frågan använder det logiska cacheläget.
- Träffar, missar, vräkningar, översvämningar – De tre raderna ger statistik om cachen, antal träffar, missar, vräkningar och översvämningar under avrättningen. Detta block inkluderar även minnesanvändningen under exekvering av en fråga.
- Indexsökning med kategori_pkey – Detta visar operationen som utför en indexskanning på kategoritabellen med hjälp av primärnyckelindex.
- Index Cond – Detta visar att indexskanningen är baserad på villkoret som matchar category_id-kolumnen i kategoritabellen.
- Planeringstid – Den här raden visar tiden det tar för frågeplanering som är 3,005 millisekunder.
- Execution Time – Slutligen visar den här raden den totala exekveringstiden för frågan som är 0,745 millisekunder.
Där har du det! En detaljerad information om exekveringen av en enkel join i PostgreSQL.
Slutsats
Du upptäckte kraften och användningen av EXPLAIN ANALYZE-satsen i PostgreSQL. EXPLAIN ANALYZE-satsen är ett kraftfullt verktyg för frågeanalys och optimering. Använd det här verktyget för att skapa effektiva och mindre resurskrävande frågor.