'I 'pandas' kan vi enkelt läsa textfilen med hjälp av metoden 'pandas'. 'Pandas' ger oss möjlighet att läsa textfilen. 'Pandas' ger olika inbyggda metoder för att läsa textfilen. Vi kommer att diskutera alla metoder i denna handledning tillsammans med alla parametrar här och kommer att förklara dem i detalj. Vi kommer också att läsa textfilen i 'pandas' genom att använda metoderna för 'pandas' i våra koder här.'
Metoder för att läsa textfilen i 'pandas'
I 'pandas' har vi tre metoder som hjälper oss att läsa textfilen. Vi har även gjort några exempel här där vi läser textfilen. Metoderna som 'pandas' tillhandahåller diskuteras nedan:
-
- Genom att använda metoden pd.read_csv() .
- Genom att använda metoden pd.read_table() .
- Genom att använda metoden pd.read_fwf() .
Nu förklarar vi syntaxen för alla dessa metoder och diskuterar också parametrarna för alla metoder i detalj i denna handledning.
Syntax för read_csv()
pd.read_csv ( 'filnamn.txt', sep =' ', rubrik =Inga, namn = [ 'Col_name1', 'Col_name2, 'Col_name2', ………….. ] )
I den här metoden lägger vi först till namnet på textfilen vars data vi vill läsa, och det är den första parametern i denna metod. Sedan placerar vi 'sep', som är en separator i den här metoden, och vi placerar utrymme här som tecknet så att det kommer att betrakta utrymmet som avgränsaren. Efter detta har vi rubrikparametern, och värdet 'None' för denna parameter används, så det kommer att skapa standardhuvudet, och om vi inte lägger till den här parametern kommer den att överväga den första raden i textfilen som rubrik. I parametern 'namn' kan vi lägga till kolumnnamnen som vi måste lägga till som rubrik.
Syntax för read_table()
pd.read_table ( 'filnamn.txt' , avgränsare = ' ' )
I den här metoden sätter vi filnamnet på textfilen som den första parametern. I avgränsaren, när vi placerar ' ', kommer det att ta mellanslagstecknet som avgränsare.
Syntax för read_fwf()
pd.read_fwf ( 'filnamn.txt' )
Denna metod tar bara en parameter, vilket är namnet på textfilen.
Nu kommer vi att använda dessa metoder för att läsa textfilerna i 'pandas'-koder och visa textfilens data på terminalen.
Exempel # 01
'Spyder'-appen är här där vi har gjort alla dessa koder som presenteras i denna handledning. Textfilen vars data vi vill läsa visas nedan. Vi kommer att använda metoden 'read_csv()' för att läsa denna textfil i 'pandas'.
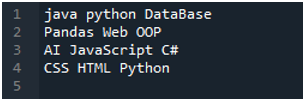
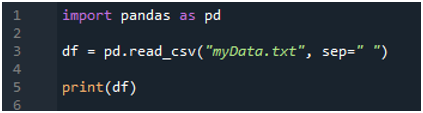
Vi importerar först 'pandas'-biblioteket eftersom vi vill använda metoden 'read_csv()', och det är metoden för 'pandas'. Vi kommer bara åt den här metoden när vi har importerat biblioteket med 'pandas'. Här nämner vi 'pandas som pd', så denna 'pd' placeras med namnet på metoden för att använda den. Efter detta skapar vi en variabel 'df' här, som används för att lagra data i textfilen efter läsning. Vi placerar metoden 'pd.read_csv()' här, som hjälper till att läsa textfilen och konvertera textfildata till DataFrame och lagra den i variabeln 'df'.
Vi har skickat filnamnet, som är 'myData.txt', här, och sedan använder vi 'sep' och tilldelar det tomma tecknet till denna 'sep'. Så detta tomma tecken fungerar som avgränsare i textfilen. Sedan använde vi 'print()' nedan, som används för att skriva ut data i textfilen. Det kommer att visa data från textfilen i DataFrame-formuläret.
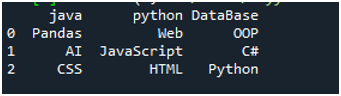
För exekvering av denna kod måste vi trycka på 'Shift+Enter' och utdata kommer att återges på 'Spyders' terminal. Resultatet av ovanstående kod visas i den givna skärmdumpen, och du kan se att data i textfilen visas som DataFrame, och den första raden i vår textfil presenteras här som kolumnnamnen för den DataFrame. Den separerar också data där mellanslagstecknet finns i textfilen.
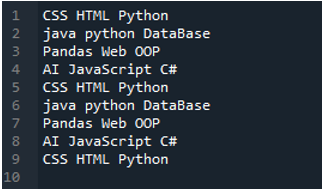
Exempel # 02
Textfilen som vi kommer att läsa i det här exemplet visas här, och vi kommer återigen att använda metoden 'read_csv()' men med andra parametrar.
“Pandas”-metoden “pd.read_csv()” används, och vi skickar tre parametrar här. Först placerar vi filnamnet, som är 'Record.txt'. Den andra parametern är parametern 'sep' och tilldelar det tomma tecknet till den, och sedan har vi den tredje parametern där vi ställer in 'huvudet' och justerar det till 'Ingen', så det kommer att skapa standardhuvudet för DataFrame när vi kör den här koden. Vi har sparat allt detta i variabeln 'My_Record' och även lagt till 'My_Record' i funktionen 'print()' för utskrift.

All data sparas i DataFrame, och den separerar data där blanksteg finns i textfilens data. Det skapade också standardhuvudet för DataFrame här eftersom vi justerade parametern 'header' till 'Ingen'.
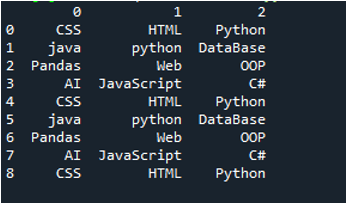
Exempel # 03
Det här exemplets textfil visas, och vi kommer återigen att använda metoden 'read_csv()' med modifierade parametrar.
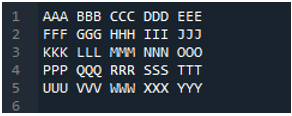
I den här koden skickas fyra parametrar här till 'pandas'-metoden 'pd.read_csv()'. Textfilens namn är den första parametern. Parametern 'sep' ges det tomma tecknet i den andra parametern. Parametern 'header' är inställd på 'None' i det tredje argumentet, och som den fjärde parametern har vi angett 'names' som kommer att visas som kolumnnamnen för DataFrame efter att ha läst textfilen, och dessa kolumnnamn är 'COL_1, COL_2, COL_3, COL_4 och COL_5'. All denna information har sparats i variabeln 'My_Record', och 'My_Record' har också lagts till i metoden 'print()' så att den kommer att skrivas ut på terminalen.

All information i textfilen renderas här som DataFrame, och den separerar även data där mellanslagen läggs till i textfilen. Den lägger också till kolumnnamnen i enlighet med detta, vilket vi har lagt till ovan i koden.
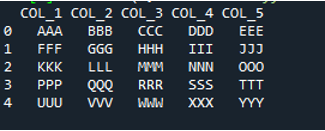
Exempel # 04
Det här är textfilen vi kommer att läsa i det här exemplet genom att använda en annan metod, metoden 'pd.read_table()'.
Metoden 'pd.read_table()' läggs till här för att läsa textfilen, och vi lägger till 'ABC.txt', som är textfilens namn. Den här metoden hjälper till att läsa textfilen, och vi har också justerat parametern 'avgränsare' till mellanslagstecknet, så det kommer också att fungera som avgränsaren som vi har förklarat ovan. Sedan sparas all textfildata i variabeln 'My_Data' och skrivs även ut här.

Den första raden i vår textfil visas här som kolumnnamnen för DataFrame, och data i textfilen skrivs ut som DataFrame. Dessutom separerar den informationen i textfilen där mellanslagstecknet finns i den.
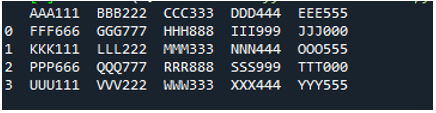
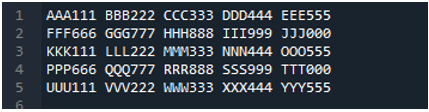
Exempel # 05
Nu innehåller textfilen data, som visas nedan. Vi kommer att använda 'read_fwf()' den här gången och kommer att visa hur den renderar data efter att ha läst textfilen.
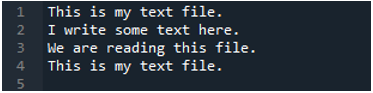
Som vi vet att denna 'read_fwf()'-metod bara tar en parameter, vilket är filnamnet som vi vill läsa. Vi lägger till 'textfile.txt' här, vilket är namnet på vår textfil och tilldelar denna pandas-metod till variabeln 'File_Data', som kommer att lagra data från denna textfil. Sedan lägger vi 'print(File_Data)' så att den också skriver ut denna data.

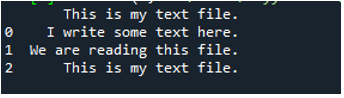
Här visas all data i textfilen. Den separerade inte data där blanksteg finns eftersom det inte finns någon parameter som 'Sep' eller 'avgränsare' i den här funktionen.
Slutsats
Denna handledning förklarar hur man läser textfilen i 'pandas' och vilka metoder som används för att läsa textfilen i 'pandas'. Vi har diskuterat alla metoder som hjälper oss att läsa textfilen i 'pandas'. Vi har utforskat tre olika metoder för 'pandas' för att läsa våra textfiler i 'pandas' i denna handledning. Vi har också förklarat syntaxen för alla metoder samt parametrarna för alla metoder i detalj här och har läst många textfiler genom att tillämpa olika metoder med alla möjliga parametrar i denna handledning.