“Comma-Separated Values (CSV) är ett av de mest mångsidiga och lättanvända dataformaten. Det är ett lättviktigt dataformat som tillåter utvecklare och applikationer att överföra och analysera data från en källa till en annan.
CSV-data lagrar data i ett tabellformat där varje kolumn separeras med ett kommatecken och en ny post tilldelas en ny rad. Detta gör det till ett mycket bra val för att exportera databaser som SQL-databaser, Cassandra-data och mer.
Det är därför ingen överraskning att du kommer att stöta på ett scenario där du behöver importera en CSV-fil till din databas.
Målet med denna handledning är att visa dig en snabb och enkel metod för att importera en CSV-fil till ditt Elasticsearch-kluster med hjälp av Kibana-instrumentpanelen.'
Låt oss hoppa in.
Krav
Innan du dyker in, se till att du har följande krav:
- Ett Elasticsearch-kluster med grön hälsostatus.
- Kibana-server ansluten till ditt Elasticsearch-kluster.
- Tillräckliga behörigheter för att hantera index i ditt kluster.
Exempel på CSV-fil
Som vanligt är det första kravet din CSV-källfil. Det är bra att se till att informationen i din CSV-fil är välformaterad och att den inte innehåller några fel.
I illustrationssyfte kommer vi att använda en gratis datauppsättning som innehåller filmer och TV-program från Amazon Prime.
Öppna din webbläsare och navigera till resursen nedan:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Följ proceduren för att ladda ner datauppsättningen till din lokala dator. Du kan extrahera det nedladdade arkivet med kommandot:
$ packa upp a~ / Nedladdningar / archive.zip
Importera CSV-fil
När du har din källfil redo kan vi fortsätta och diskutera hur du importerar den.
Börja med att gå över till din Kibana-hempanel och välj alternativet 'ladda upp en fil'.
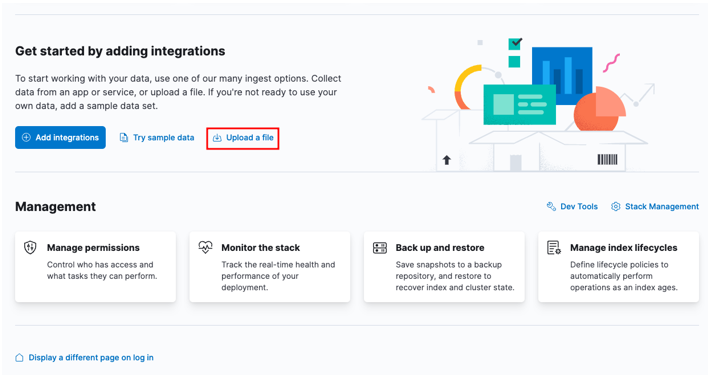
Leta reda på mål-CSV-filen du vill importera i startfönstret.
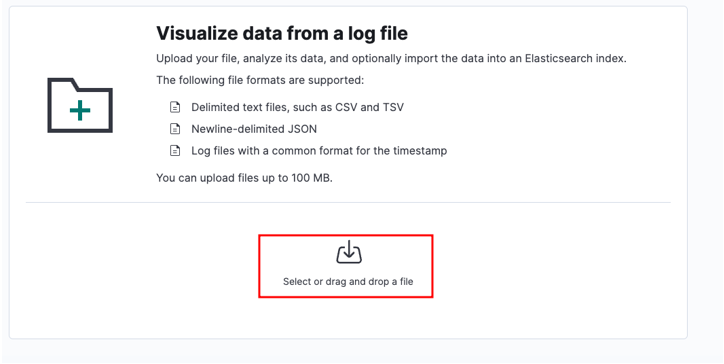
Välj din källfil och klicka på ladda upp.
Tillåt Elasticsearch och Kibana att analysera den uppladdade filen. Detta kommer att analysera CSV-filen och bestämma dataformat, fält, datatyper etc.
OBS: Beroende på din klusterkonfiguration och datastorleken kan denna process ta ett tag. Se till att masternoden svarar för att undvika timeouts.
När processen är klar bör du få ett urval av ditt filinnehåll och filstatistiken som analyserats av Elastic.
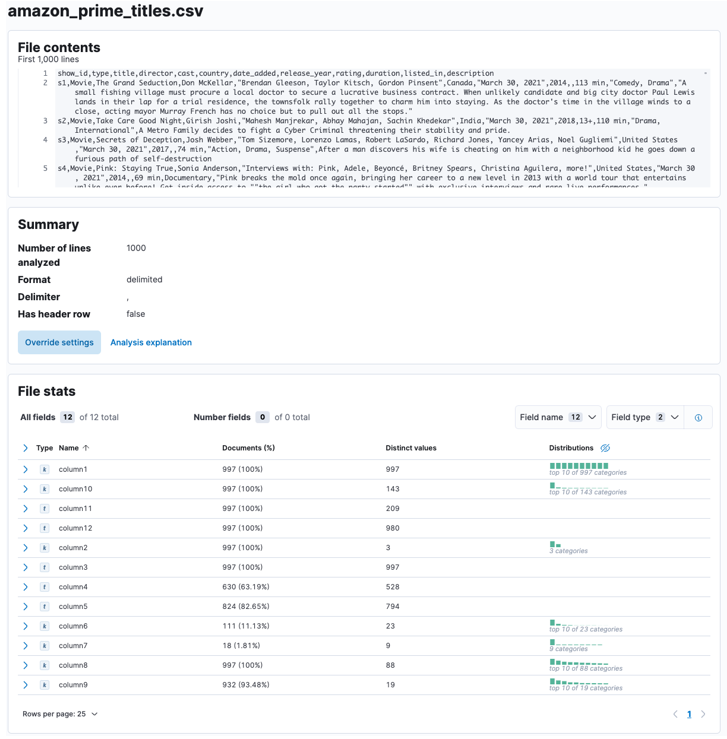
Du kan skräddarsy flera parametrar, till exempel avgränsaren, rubrikrader, etc. Till exempel kan vi anpassa utdata ovan för att tala om för Elastic att vår CSV-fil innehåller rubrikfiler.
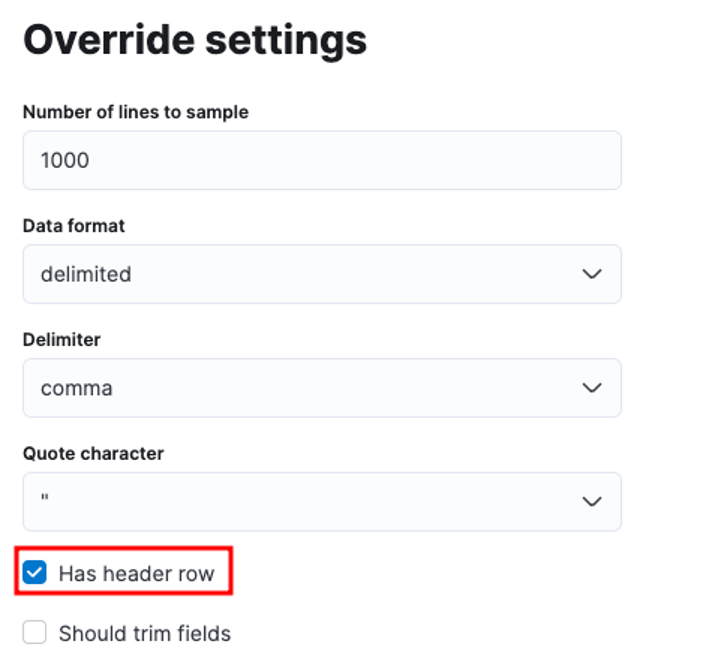
Vi kan sedan klicka på tillämpa och analysera data på nytt. Detta bör formatera data i rätt format, inklusive fälten.
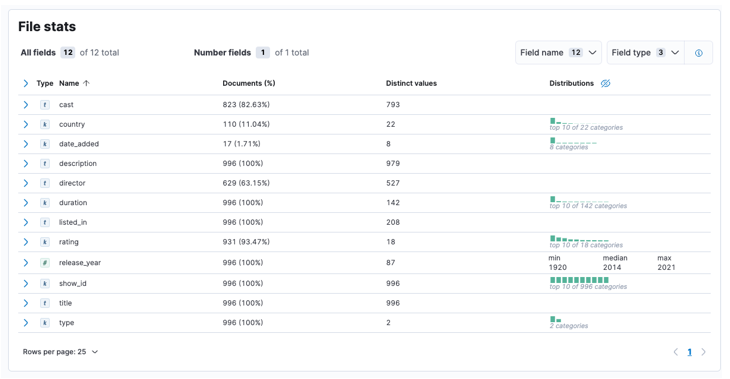
Därefter kan vi klicka på importera för att fortsätta till den importerade instrumentpanelen.
Här måste vi skapa ett index där CSV-data lagras. Du kan tilldela vilket namn som helst till ditt index.
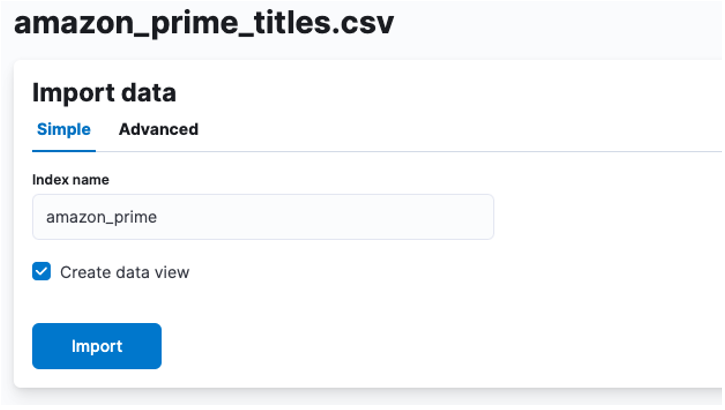
Om du vill anpassa dina indexegenskaper, såsom antalet skärvor, repliker, mappningar, etc. Välj det avancerade alternativet och justera dina inställningar som ditt hjärta önskar.
Klicka slutligen på importera och se när Kibana gör sin 'magi'. När du är klar kan du komma åt ditt index antingen via Elasticsearch API eller använda Kibanas instrumentpanel.
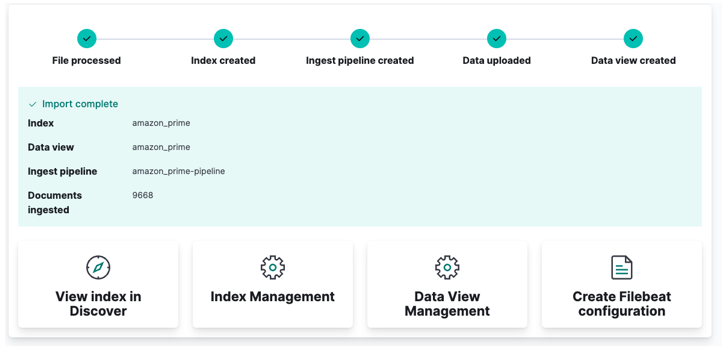
Och du är klar!!
Slutsats
I det här inlägget täckte vi processen för att hämta och importera din CSV-datauppsättning till ditt Elasticsearch-kluster med hjälp av Kibana-instrumentpanelen.
Tack för att du läste och glad kodning!!