Den här guiden kommer att illustrera hur du använder VectorStoreRetrieverMemory med hjälp av LangChain-ramverket.
Hur man använder VectorStoreRetrieverMemory i LangChain?
VectorStoreRetrieverMemory är biblioteket i LangChain som kan användas för att extrahera information/data från minnet med hjälp av vektorlagren. Vektorlager kan användas för att lagra och hantera data för att effektivt extrahera informationen enligt uppmaningen eller frågan.
För att lära dig hur du använder VectorStoreRetrieverMemory i LangChain, gå helt enkelt igenom följande guide:
Steg 1: Installera moduler
Starta processen med att använda minneshämtningen genom att installera LangChain med pip-kommandot:
pip installera langkedja
Installera FAISS-modulerna för att få data med hjälp av den semantiska likhetssökningen:
pip installera faiss-gpu 
Installera chromadb-modulen för att använda Chroma-databasen. Det fungerar som vektorlager för att bygga minnet för retrievern:
pip installera chromadb 
En annan modul tiktoken behövs för att installera som kan användas för att skapa tokens genom att konvertera data till mindre bitar:
pip installera tiktoken 
Installera OpenAI-modulen för att använda dess bibliotek för att bygga LLM:er eller chatbots med hjälp av dess miljö:
pip installera openai 
Ställ in miljön på Python IDE eller notebook med API-nyckeln från OpenAI-kontot:
importera duimportera getpass
du . ungefär [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Steg 2: Importera bibliotek
Nästa steg är att hämta biblioteken från dessa moduler för att använda minneshämtaren i LangChain:
från långkedja. uppmaningar importera PromptMallfrån datum Tid importera datum Tid
från långkedja. llms importera OpenAI
från långkedja. inbäddningar . openai importera OpenAIE-inbäddningar
från långkedja. kedjor importera ConversationChain
från långkedja. minne importera VectorStoreRetrieverMemory
Steg 3: Initiera Vector Store
Den här guiden använder Chroma-databasen efter import av FAISS-biblioteket för att extrahera data med inmatningskommandot:
importera faissfrån långkedja. läkare importera InMemoryDocstore
#importera bibliotek för att konfigurera databaserna eller vektorlagren
från långkedja. vektorbutiker importera FAISS
#skapa inbäddningar och texter för att lagra dem i vektorbutikerna
inbäddningsstorlek = 1536
index = faiss. IndexFlatL2 ( inbäddningsstorlek )
inbäddning_fn = OpenAIE-inbäddningar ( ) . embed_query
vectorstore = FAISS ( inbäddning_fn , index , InMemoryDocstore ( { } ) , { } )
Steg 4: Bygg retriever med stöd av en vektorbutik
Bygg upp minnet för att lagra de senaste meddelandena i konversationen och få kontexten för chatten:
retriever = vectorstore. as_retriever ( search_kwargs = dikt ( k = 1 ) )minne = VectorStoreRetrieverMemory ( retriever = retriever )
minne. save_context ( { 'inmatning' : 'Jag gillar att äta pizza' } , { 'produktion' : 'fantastisk' } )
minne. save_context ( { 'inmatning' : 'Jag är bra på fotboll' } , { 'produktion' : 'ok' } )
minne. save_context ( { 'inmatning' : 'Jag gillar inte politiken' } , { 'produktion' : 'Säker' } )
Testa modellens minne med hjälp av indata från användaren med dess historik:
skriva ut ( minne. load_memory_variables ( { 'prompt' : 'vilken sport ska jag titta på?' } ) [ 'historia' ] ) 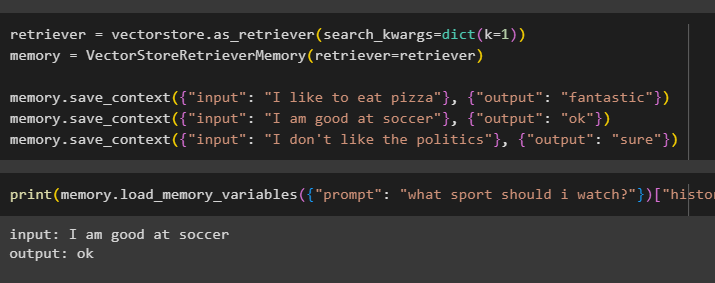
Steg 5: Använda Retriever i en kedja
Nästa steg är användningen av en minneshämtning med kedjorna genom att bygga LLM med OpenAI()-metoden och konfigurera promptmallen:
llm = OpenAI ( temperatur = 0 )_DEFAULT_MALL = '''Det är en interaktion mellan en människa och en maskin
Systemet producerar användbar information med detaljer med hjälp av sammanhang
Om systemet inte har svaret för dig, säger det helt enkelt att jag inte har svaret
Viktig information från konversationen:
{historia}
(om texten inte är relevant använd den inte)
Aktuell chatt:
Människan: {input}
AI:'''
PROMPT = PromptMall (
input_variables = [ 'historia' , 'inmatning' ] , mall = _DEFAULT_MALL
)
#configure ConversationChain() med hjälp av värdena för dess parametrar
konversation_med_sammanfattning = ConversationChain (
llm = llm ,
prompt = PROMPT ,
minne = minne ,
mångordig = Sann
)
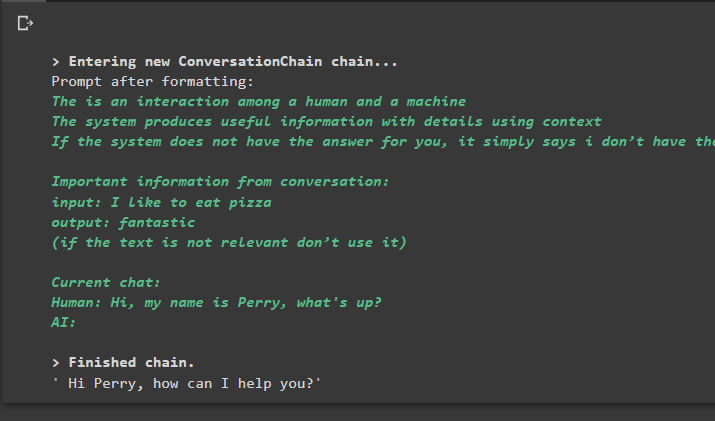
konversation_med_sammanfattning. förutse ( inmatning = 'Hej, jag heter Perry, vad är det?' )
Produktion
Genom att köra kommandot körs kedjan och visar svaret från modellen eller LLM:
Fortsätt med konversationen med hjälp av prompten baserad på data som lagras i vektorlagret:
konversation_med_sammanfattning. förutse ( inmatning = 'vilken är min favoritsport?' ) 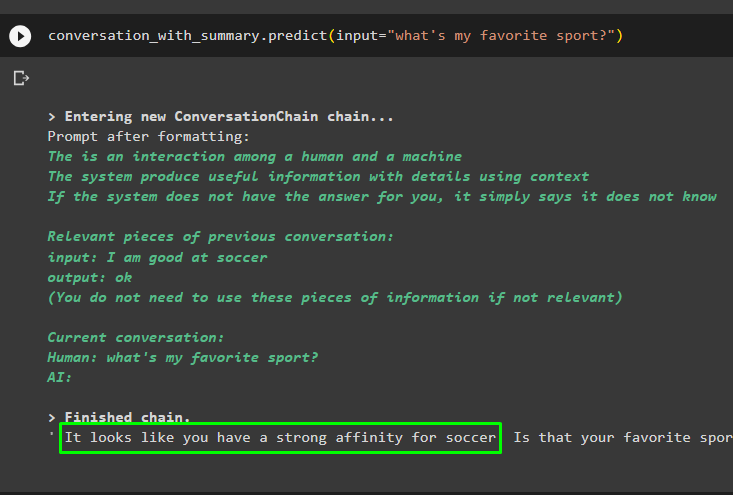
De tidigare meddelandena lagras i modellens minne som kan användas av modellen för att förstå meddelandets sammanhang:
konversation_med_sammanfattning. förutse ( inmatning = 'Vad är min favoritmat' ) 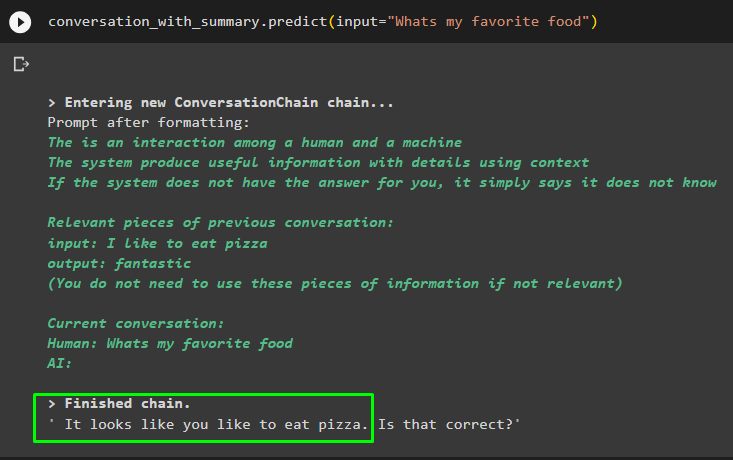
Få svaret på modellen i ett av de tidigare meddelandena för att kontrollera hur minneshämtningen fungerar med chattmodellen:
konversation_med_sammanfattning. förutse ( inmatning = 'Vad heter jag?' )Modellen har korrekt visat utdata med hjälp av likhetssökningen från data lagrade i minnet:
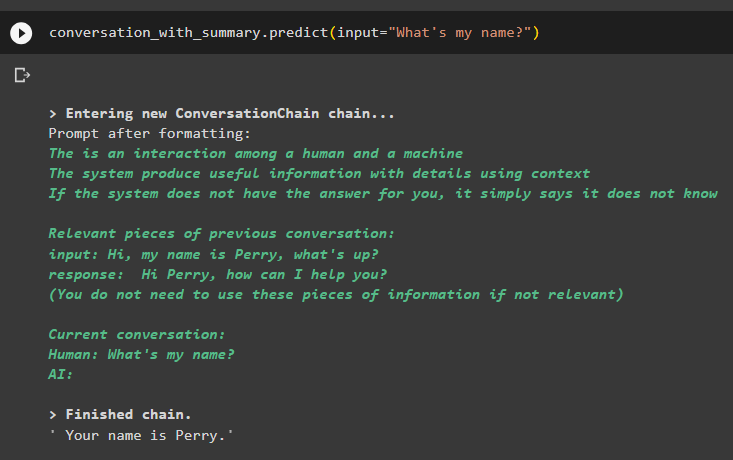
Det handlar om att använda vektorbutiksretrievern i LangChain.
Slutsats
För att använda minneshämtningen baserad på en vektorbutik i LangChain, installera helt enkelt modulerna och ramverken och ställ in miljön. Efter det importerar du biblioteken från modulerna för att bygga databasen med Chroma och ställer sedan in promptmallen. Testa retrievern efter att ha lagrat data i minnet genom att starta konversationen och ställa frågor relaterade till tidigare meddelanden. Den här guiden har utvecklat processen för att använda VectorStoreRetrieverMemory-biblioteket i LangChain.