Vad är Kubernetes nodeSelector?
En nodeSelector är en schemaläggningsrestriktion i Kubernetes som specificerar en karta i form av en nyckel: värdepar anpassade podväljare och nodetiketter används för att definiera nyckeln, värdeparet. NodeSelector märkt på noden bör matcha med nyckeln: värdeparet så att en viss pod kan köras på en specifik nod. För att schemalägga podden används etiketter på noder och nodeSelectors på pods. OpenShift Container Platform schemalägger poddarna på noderna med hjälp av nodeSelector genom att matcha etiketterna.
Dessutom används etiketter och nodeSelector för att styra vilken pod som ska schemaläggas på en specifik nod. När du använder etiketterna och nodeSelector, märk noden först så att poddarna inte blir avschemalagda och lägg sedan till nodeSelector till poden. För att placera en viss pod på en viss nod används nodeSelector, medan den klusteromfattande nodeSelector låter dig placera en ny pod på en viss nod som finns var som helst i klustret. Project nodeSelector används för att placera den nya podden på en viss nod i projektet.
Förutsättningar
För att använda Kubernetes nodeSelector, se till att du har följande verktyg installerade i ditt system:
- Ubuntu 20.04 eller någon annan senaste version
- Minikube-kluster med minst en arbetarnod
- Kubectl kommandoradsverktyg
Nu går vi till nästa avsnitt där vi kommer att demonstrera hur du kan använda nodeSelector på ett Kubernetes-kluster.
nodeSelector-konfiguration i Kubernetes
En pod kan begränsas till att endast kunna köras på en specifik nod genom att använda nodeSelector. NodeSelector är en nodvalsbegränsning som specificeras i podspecifikationen PodSpec. Med enkla ord är nodeSelector en schemaläggningsfunktion som ger dig kontroll över podden för att schemalägga poden på en nod som har samma etikett som specificerats av användaren för nodeSelector-etiketten. För att använda eller konfigurera nodeSelector i Kubernetes behöver du minikube-klustret. Starta minikube-klustret med kommandot nedan:
> starta minikube
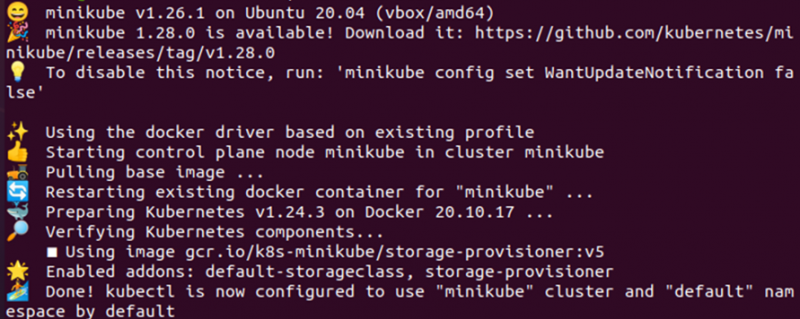
Nu när minikube-klustret har startats framgångsrikt kan vi starta implementeringen av konfigurationen av nodeSelector i Kubernetes. I det här dokumentet kommer vi att guida dig till att skapa två distributioner, en är utan nodeSelector och den andra är med nodeSelector.
Konfigurera distribution utan nodeSelector
Först kommer vi att extrahera detaljerna för alla noder som för närvarande är aktiva i klustret genom att använda kommandot nedan:
> kubectl hämta noderDetta kommando kommer att lista alla noder som finns i klustret med uppgifter om namn, status, roller, ålder och versionsparametrar. Se exempelutdata nedan:

Nu kommer vi att kontrollera vilka fläckar som är aktiva på noderna i klustret så att vi kan planera att distribuera poddarna på noden därefter. Kommandot nedan ska användas för att få beskrivningen av fläckarna applicerade på noden. Det bör inte finnas några fläckar aktiva på noden så att kapslarna lätt kan placeras ut på den. Så låt oss se vilka fläckar som är aktiva i klustret genom att utföra följande kommando:
> kubectl beskriver noder minikube | grepp Bismak 
Från utgången ovan kan vi se att det inte finns någon fläck på noden, bara exakt vad vi behöver för att distribuera pods på noden. Nu är nästa steg att skapa en distribution utan att ange någon nodeSelector i den. För den delen kommer vi att använda en YAML-fil där vi kommer att lagra nodeSelector-konfigurationen. Kommandot som bifogas här kommer att användas för att skapa YAML-filen:
> nano deplond.yamlHär försöker vi skapa en YAML-fil med namnet deplond.yaml med nano-kommandot.
När vi kör detta kommando kommer vi att ha en deplond.yaml-fil där vi kommer att lagra distributionskonfigurationen. Se distributionskonfigurationen nedan:
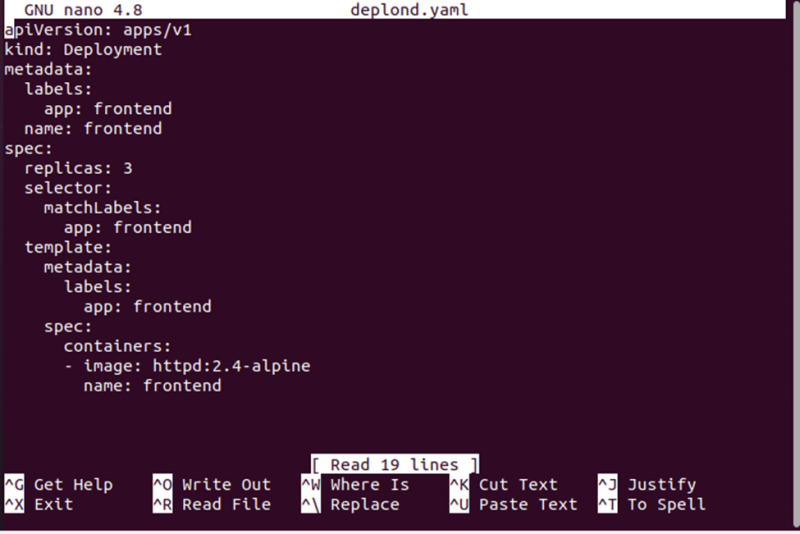
Nu kommer vi att skapa distributionen med hjälp av distributionskonfigurationsfilen. Filen deplond.yaml kommer att användas tillsammans med kommandot 'create' för att skapa konfigurationen. Se hela kommandot nedan:
> kubectl skapa -f deplond.yaml 
Som visas ovan har distributionen skapats framgångsrikt men utan nodeSelector. Låt oss nu kontrollera noderna som redan är tillgängliga i klustret med kommandot nedan:
> kubectl få baljorDetta kommer att lista alla tillgängliga poddar i klustret. Se utgången nedan:
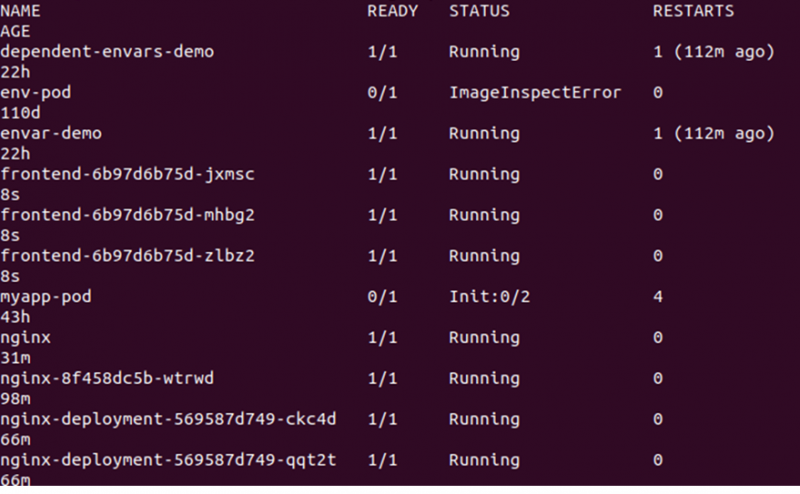
Därefter måste vi ändra antalet repliker, vilket kan göras genom att redigera filen deplond.yaml. Öppna bara filen deplond.yaml och redigera värdet på replikerna. Här ändrar vi replikerna: 3 till replikerna: 30. Se modifieringen i ögonblicksbilden nedan:
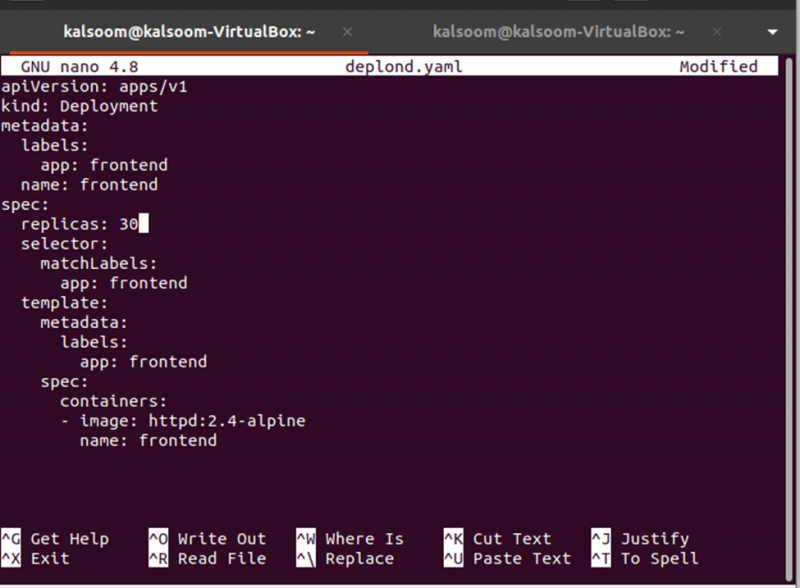
Nu måste ändringarna tillämpas på distributionen från distributionsdefinitionsfilen och det kan göras genom att använda följande kommando:
> kubectl tillämpas -f deplond.yaml 
Låt oss nu kontrollera mer detaljer om poddarna genom att använda -o wide-alternativet:
> kubectl få baljor -De bred 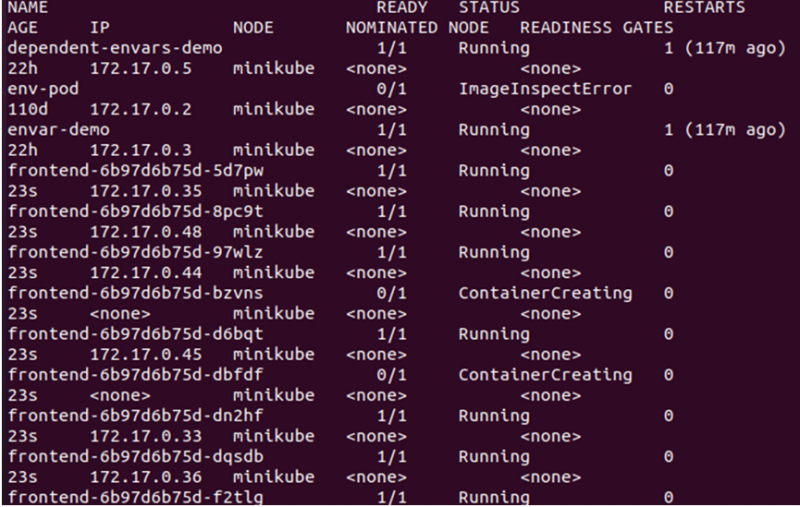
Från utgången ovan kan vi se att de nya noderna har skapats och schemalagts på noden eftersom det inte finns någon fläck aktiv på noden vi använder från klustret. Därför måste vi specifikt aktivera en taint för att säkerställa att poddarna bara schemaläggs på den önskade noden. För det måste vi skapa etiketten på masternoden:
> kubectl etikettnoder master on-master= SannKonfigurera distribution med nodeSelector
För att konfigurera distributionen med en nodeSelector kommer vi att följa samma process som har följt för konfigurationen av distributionen utan någon nodeSelector.
Först kommer vi att skapa en YAML-fil med kommandot 'nano' där vi behöver lagra konfigurationen av distributionen.
> nano nd.yamlSpara nu distributionsdefinitionen i filen. Du kan jämföra båda konfigurationsfilerna för att se skillnaden mellan konfigurationsdefinitionerna.
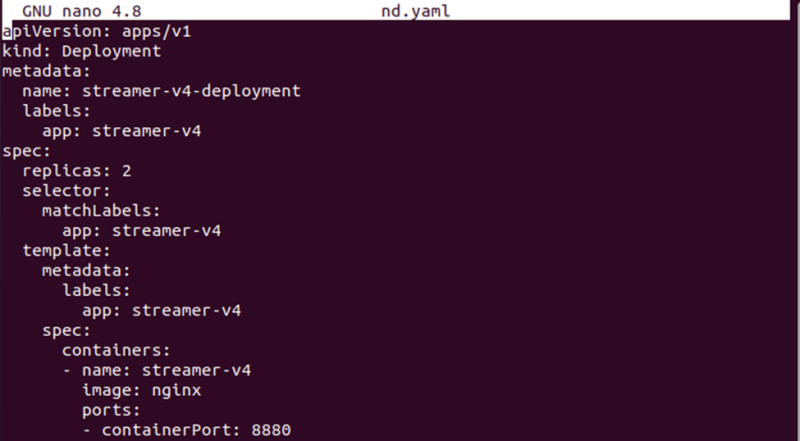

Skapa nu distributionen av nodeSelector med kommandot nedan:
> kubectl skapa -f nd.yaml 
Få information om kapslarna genom att använda flaggan -o wide:
> kubectl få baljor -De bred 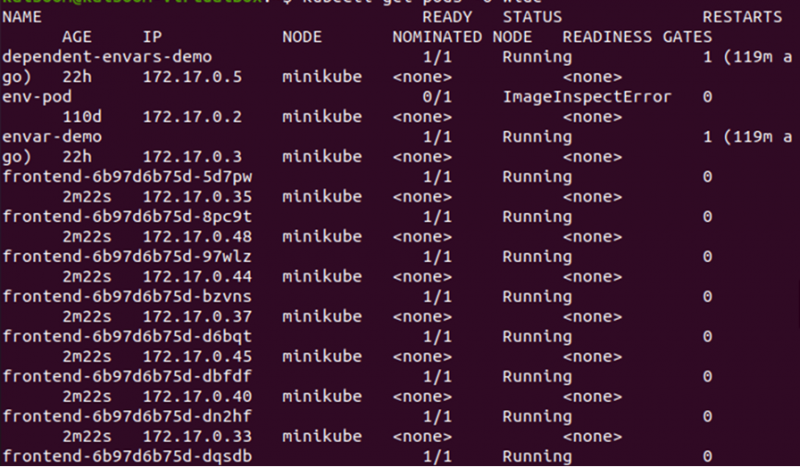
Från utgången som ges ovan kan vi märka att poddarna distribueras på minikube-noden. Låt oss ändra antalet repliker för att kontrollera var de nya poddarna distribueras i klustret.
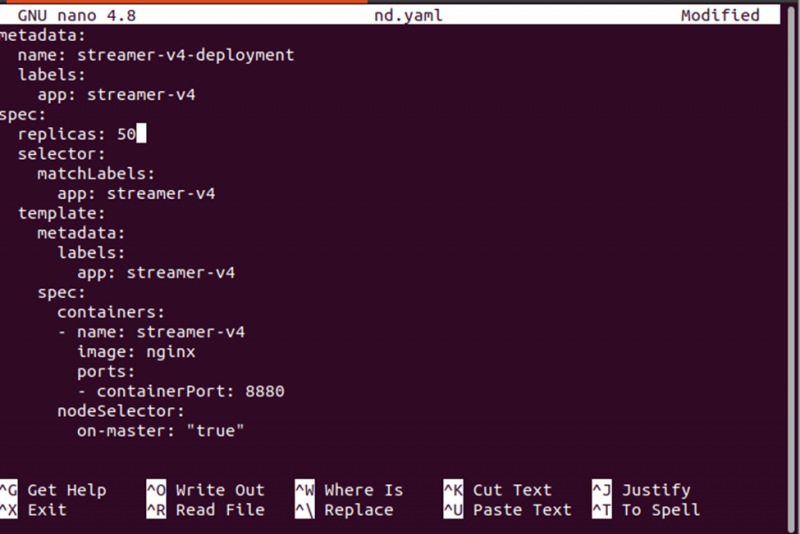
Tillämpa de nya ändringarna på distributionen genom att använda följande kommando:
> kubectl tillämpas -f nd.yaml 
Slutsats
I den här artikeln hade vi en översikt över nodeSelector-konfigurationsbegränsningen i Kubernetes. Vi lärde oss vad en nodeSelector är i Kubernetes och med hjälp av ett enkelt scenario lärde vi oss hur man skapar en distribution med och utan nodeSelector-konfigurationsbegränsningar. Du kan hänvisa till den här artikeln om du är ny på nodeSelector-konceptet och hittar all relevant information.