Snabb översikt
Det här inlägget kommer att visa:
Hur man implementerar ReAct-logiken med Document Store i LangChain
- Installera ramar
- Tillhandahåller OpenAI API-nyckel
- Importera bibliotek
- Använder Wikipedia Explorer
- Testar modellen
Hur implementerar man ReAct-logiken med Document Store i LangChain?
Språkmodellerna tränas på en enorm pool av data skriven på naturliga språk som engelska, etc. Data hanteras och lagras i dokumentlagren och användaren kan enkelt ladda in data från butiken och träna modellen. Modellträningen kan ta flera iterationer eftersom varje iteration gör modellen mer effektiv och förbättrad.
För att lära dig processen att implementera ReAct-logik för att arbeta med dokumentarkivet i LangChain, följ helt enkelt denna enkla guide:
Steg 1: Installera ramverk
Kom först igång med processen att implementera ReAct-logiken för att arbeta med dokumentarkivet genom att installera LangChain-ramverket. Installation av LangChain-ramverket kommer att få alla nödvändiga beroenden för att hämta eller importera biblioteken för att slutföra processen:
pip installera langkedja
Installera Wikipedia-beroendena för den här guiden eftersom den kan användas för att få dokumentlagren att fungera med ReAct-logiken:
pip installera wikipedia 
Installera OpenAI-modulerna med pip-kommandot för att hämta dess bibliotek och bygga stora språkmodeller eller LLM:er:
pip installera openai 
Steg 2: Tillhandahåller OpenAI API-nyckel
Efter att ha installerat alla nödvändiga moduler, helt enkelt sätta upp miljön använda API-nyckeln från OpenAI-kontot med följande kod:
importera duimportera getpass
du . ungefär [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Steg 3: Importera bibliotek
När miljön har ställts in, importera biblioteken från LangChain som krävs för att konfigurera ReAct-logiken för att arbeta med dokumentlagren. Använda LangChain-agenter för att få DocstoreExplaorer och agenter med dess typer för att konfigurera språkmodellen:
från långkedja. llms importera OpenAIfrån långkedja. läkare importera Wikipedia
från långkedja. agenter importera initialize_agent , Verktyg
från långkedja. agenter importera AgentType
från långkedja. agenter . reagera . bas importera DocstoreExplorer
Steg 4: Använd Wikipedia Explorer
Konfigurera ' läkare ” variabel med metoden DocstoreExplorer() och anropa metoden Wikipedia() i dess argument. Bygg den stora språkmodellen med OpenAI-metoden med ' text-davinci-002 ” modell efter att ha ställt in verktygen för agenten:
läkare = DocstoreExplorer ( Wikipedia ( ) )verktyg = [
Verktyg (
namn = 'Sök' ,
func = läkare. Sök ,
beskrivning = 'Det används för att ställa frågor/uppmaningar med sökningen' ,
) ,
Verktyg (
namn = 'Slå upp' ,
func = läkare. slå upp ,
beskrivning = 'Det används för att ställa frågor/uppmaningar med uppslag' ,
) ,
]
llm = OpenAI ( temperatur = 0 , modellnamn = 'text-davinci-002' )
#definiera variabeln genom att konfigurera modellen med agenten
reagera = initialize_agent ( verktyg , llm , ombud = AgentType. REACT_DOCSTORE , mångordig = Sann )
Steg 5: Testa modellen
När modellen är byggd och konfigurerad, ställ in frågesträngen och kör metoden med frågevariabeln i dess argument:
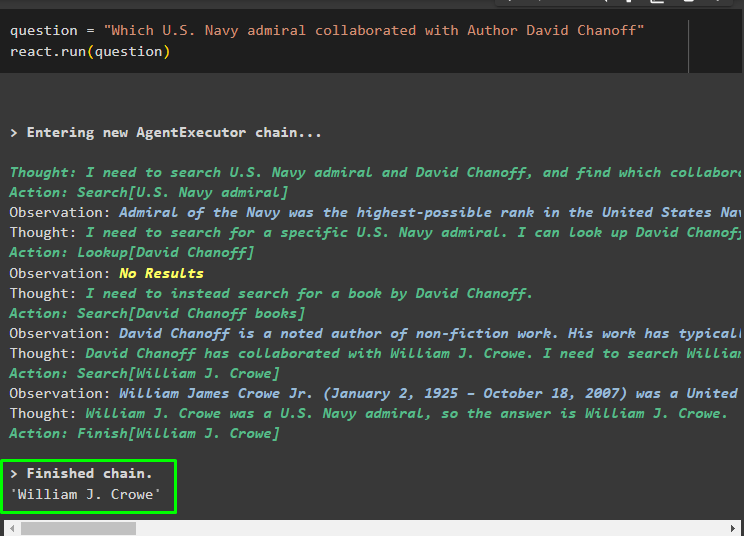
fråga = 'Vilken amerikanska flottans amiral samarbetade med författaren David Chanoff'reagera. springa ( fråga )
När frågevariabeln exekveras har modellen förstått frågan utan någon extern promptmall eller utbildning. Modellen tränas automatiskt med den modell som laddades upp i föregående steg och genererar text därefter. ReAct-logiken arbetar med dokumentlagren för att extrahera information baserat på frågan:
Ställ en annan fråga från data som tillhandahålls till modellen från dokumentbutikerna och modellen kommer att extrahera svaret från butiken:
fråga = 'Författaren David Chanoff har samarbetat med William J Crowe som tjänade under vilken president?'reagera. springa ( fråga )
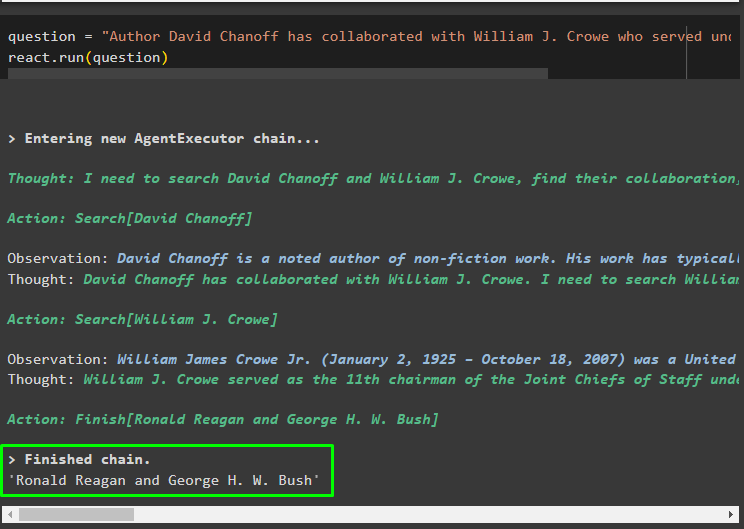
Det handlar om att implementera ReAct-logiken för att arbeta med dokumentarkivet i LangChain.
Slutsats
För att implementera ReAct-logiken för arbete med dokumentarkivet i LangChain, installera modulerna eller ramverken för att bygga språkmodellen. Efter det, ställ in miljön för OpenAI för att konfigurera LLM och ladda modellen från dokumentarkivet för att implementera ReAct-logiken. Den här guiden har utvecklat implementeringen av ReAct-logiken för att arbeta med dokumentarkivet.