'Pandas' är ett utmärkt språk för att utföra analys av data på grund av dess stora ekosystem av datacentrerade pythonpaket. Det gör analysen och importen av båda faktorerna lättare. Standardavvikelsen är en 'typisk' avvikelse härledd från medelvärdet. Det används mycket, eftersom det returnerar de ursprungliga måttenheterna för dataramen. Pandaerna använde std() för att beräkna standardavvikelsen. Standardavvikelsen kan beräknas från de givna värdena som kan finnas i dataramen i form av en rad eller kolumn. Vi kommer att implementera alla möjliga sätt på vilka pandas standardavvikelse används. För implementering av koden kommer vi att använda verktyget 'spyder' eftersom det är skrivet i en pythonvänlig miljö.'
Syntax
'df.std ( ) ”
Följande syntax används för att beräkna standardavvikelsen i dataramen. 'df' i dataramen är förkortningen av 'dataram'. Vad gör standardavvikelsen? Den mäter hur utökad den nödvändiga informationen är. Ju mer utvidgade höga värden, desto högre bör standardavvikelsen uppstå.
Lämna tillbaka
Pandas standardavvikelse returnerar dataramen om nivån anges baserat på kravet.
Observera att funktionen 'std()' automatiskt kommer att ignorera 'NaN'-värdena i 'df' medan den beräknar pandas standardavvikelse. 'NaN' kan förklaras som 'inte ett tal', vilket betyder att det inte finns något värde tilldelat en viss.
Följande är metoderna som kommer att utföras med exempel på pandornas standardavvikelse:
-
- Pandas standardavvikelseberäkning i en enda kolumn.
- Pandas standardavvikelseberäkning i flera kolumner.
- Pandas standardavvikelseberäkning av alla numeriska kolumner.
- pandas standardavvikelse med axeln = 1.
- pandas standardavvikelse med axeln = 0.
Skapar dataramen för beräkning av standardavvikelse i pandor
Öppna först programvaran 'spyder'. Importera nu pandasbiblioteket som pd. Vi kommer att skapa en dataram som består av en resultattavla med termer som 'x', 'y' och 'z' med deras poäng som '22', '10', '11', '16', '12', '45'. ', '36' och '40'. Vi har också deras assistvärden som '8', '9', '13', '7', '22', '24', '4' och '6', med returvärden som '17', ' 14”, “3”, 5”, “9”, “8”, “7” och “4”.
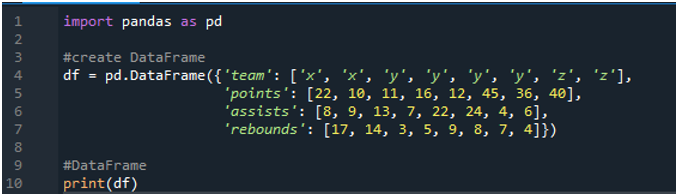
Skärmarna visar den skapade dataramen enligt värdena som tilldelats i koden:

Exempel # 01: Pandas standardavvikelseberäkning i en enda kolumn
I det här exemplet kommer vi att beräkna standardavvikelsen för en enskild kolumn i pandas dataram. Dataramen har värdena för laget som 'u', 'v' och 'b' med deras poäng som '44', '33', '22', '44', '45', '88', '96 ” och ”78”. Värdena för assist är som '7', '8', '9', '10', '11', '14', '18' och '17' som också har värdena för returer som '11', ' 9”, “8”, “7”, “6”, “5”, “4” och “3”. Kolumnen 'punkter' väljs från dataramen för att beräkna standardavvikelsen för en kolumn.
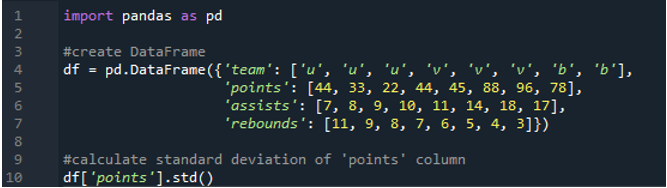
Utgången visar standardavvikelsen beräknad för kolumnen 'punkter':

Exempel # 02: Pandas standardavvikelseberäkning i flera kolumner
I det här exemplet kommer vi att utföra beräkningar av pandas standardavvikelse i flera kolumner. I denna dataram är data återigen från sportresultattavlan med värdena för laget som 'n', 'w' och 't' med poängen som '33', '22', '66', '55', '44', '88', '99' och '77'. Assisten som '9', '7', '8', '11', '16', '14', '12' och '13' och returer som '5', '8', '1', ' 2”, “3”, “4”, “6” och “7”. Här kommer vi att beräkna standardavvikelsen för de två kolumnerna 'points' och 'rebounds' genom att använda funktionen std() applicerad på dataramen.
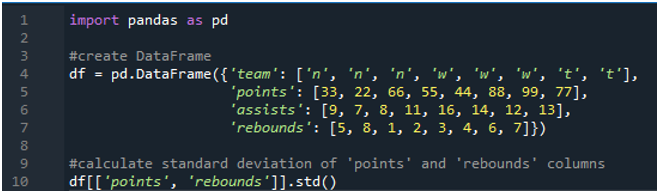
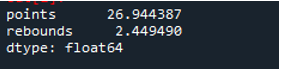
Som vi ser visar utdata att standardavvikelsen kom upp som 26,944387 i poängkolumnen respektive 2,449490 i returkolumnen.
Exempel # 03: Pandas standardavvikelseberäkning av alla numeriska kolumner
Nu har vi lärt oss hur man beräknar standardavvikelsen för enstaka och flera rader. Vad händer om vi inte vill specificera alla kolumnnamn i dataramen och beräkna hela dataramen? Detta är möjligt med bara en enkel funktionsimplementering av pandas standardavvikelse för beräkning av hela dataramen i resultaten. Dataramen här består av 'l', 'm' och 'o' med poängvärdena '33', '36', '79', '78', '58', '55' och två lag gör samma poäng det vill säga '25'. Assisten är som '1', '2', '3', '4', '6', '9', '5' och '7' och deras returer som '14', '10', '2' , '5', '8', '3', '6' och '9'. Vi kan beräkna alla standardkolumnavvikelser av pandor i dataramen med hjälp av pandas 'std()'-funktion.
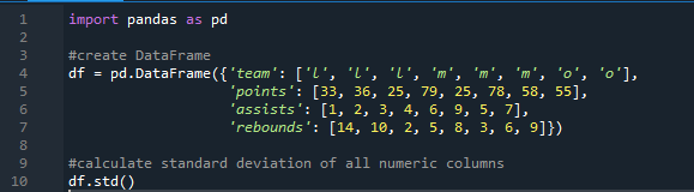
Displayen har den beräknade standardavvikelsen för hela 'df' som visas nedan; vi kan också märka att pandorna inte har beräknat standardavvikelsen för den första kolumnen, som är 'lag', eftersom det inte är en numerisk kolumn.
Exempel # 04: Pandas standardavvikelse med axeln = 0
I det här exemplet har dataramarna sportens lag som 'g', 'h' och 'k' med ytterligare data. Här kommer vi att beräkna standardavvikelsen genom att använda axeln som '0', en parameter som används i pandas standardavvikelse. Detta argument beräknar standardavvikelsen kolumnvis för dataramen.
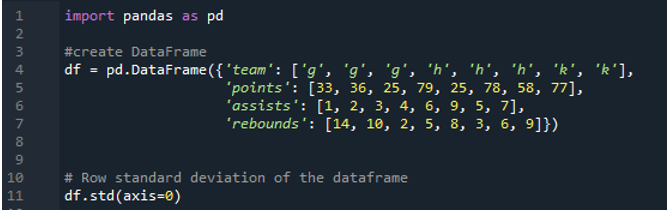
Följande utdata visar resultaten i kolumner för den beräknade standardavvikelsen. Poängkolumnen har den beräknade standardavvikelsen som '24,0313062', assistskolumnen har den beräknade standardavvikelsen som '2,669270' och returkolumnens beräknade standardavvikelse visas som '3,943802'.
Exempel # 05: Pandas standardavvikelse med axeln = 1
Här kommer vi att använda axelparametern tilldelad som '1' för att beräkna standardavvikelsen i pandor. Vilken skillnad kan axel '1' göra? Argumentet '1'-axeln beräknar den radvisa standardavvikelsen för de numeriska värdena i dataramen. Dataramen har de tre lagen som 's', 'd' och 'e', med tillägg av datakolumner skapade som poäng för laget, lagets assist och lagets returer. Alla riktningar tilldelas olika värden i dataramen. Den här axelparametern är en sådan game changer eftersom vi vid tiden måste arbeta med data där vi vill att den ska vara i en kolumn plus poäng beräknad på utförd standardavvikelse.
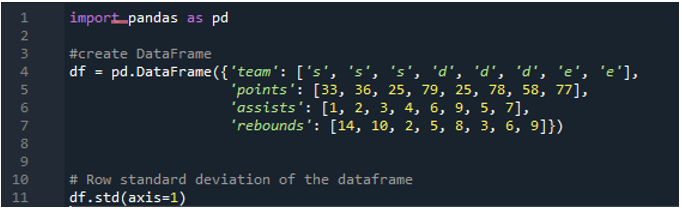
Följande utdata visar standardavvikelsen beräknad i en rad av dataramen:
Slutsats
Pandas standardavvikelse är en mycket teknisk funktion, vilket är en mycket fördelaktig funktion eftersom den hittar standardavvikelsen för entusiasmpakten för pandor dataramar. I denna ledare har vi studerat metoderna för att beräkna standardavvikelsen hos pandor. Vi har gjort enkolumnsberäkningar av standardavvikelse och flera kolumner och även beräknat standardavvikelsen för hela dataramen tillsammans. Alla strategier fungerar bra så länge de används konsekvent och med önskat resultat.