Syntax
df [ ( cond_1 ) & ( cond_2 ) ]Exempel 01
Vi gör dessa koder på 'Spyder'-appen och kommer att använda 'OCH'-operatören i våra villkor i 'pandas' här. När vi gör pandakoderna så måste vi först importera 'pandas som pd' och kommer att få sin metod genom att bara sätta 'pd' i vår kod. Sedan genererar vi en ordbok med namnet 'Cond', och data vi infogar här är 'A1', 'A2' och 'A3' är kolumnnamnen, och vi lägger till '1, 2 och 3' i ' A1', i 'A2' finns '2, 6 och 4' och den sista 'A3' innehåller '3, 4 och 5'.
Sedan övergår vi till att göra DataFrame för denna ordbok genom att använda 'pd.DataFrame' här. Detta kommer att returnera DataFrame för ovanstående ordboksdata. Vi återger det också genom att tillhandahålla 'print ()' här, och efter detta tillämpar vi vissa villkor och använder även '&'-operatorn i detta tillstånd. Det första villkoret här är att 'A1 >= 1', och sedan sätter vi operatorn '&' och sätter ett annat villkor som är 'A2 < 5'. När vi kör detta kommer det att returnera resultatet om 'A1 >=1' och även 'A2 < 5'. Om båda villkoren är uppfyllda här, kommer resultatet att visas, och om något av dem inte är uppfyllt här, kommer det inte att visa några data.
Den kontrollerar både 'A1' och 'A2' kolumnerna i DataFrame och returnerar sedan resultatet. Resultatet visas på skärmen eftersom vi använder 'print ()'-satsen.
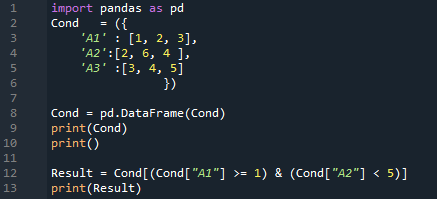
Resultatet är här. Den visar all data som vi har infogat i DataFrame och kontrollerar sedan båda villkoren. Den returnerar de rader där 'A1 >=1' och även 'A2 < 5'. Vi får två rader i denna utgång eftersom båda villkoren är uppfyllda i två rader.
Exempel 02
I det här exemplet skapar vi DataFrame direkt efter att ha importerat 'pandas som pd'. 'Team' DataFrame skapas här, med data som innehåller fyra kolumner. Den första kolumnen är kolumnen 'lag' där vi lägger in 'A, A, B, B, B, B, C, C'. Sedan är kolumnen bredvid 'lagen' 'poäng', där vi infogar '25, 12, 15, 14, 19, 23, 25 och 29'. Efter detta är kolumnen vi har 'Ut', och vi lägger också till data i den som '5, 7, 7, 9, 12, 9, 9 och 4'. Vår sista kolumn här är kolumnen 'rebounds' som också innehåller vissa numeriska data, som är '11, 8, 10, 6, 6, 5, 9 och 12'.
DataFrame är färdig här, och nu måste vi skriva ut denna DataFrame, så för detta placerar vi 'print ()' här. Vi vill få lite specifik data från denna DataFrame, så vi ställer några villkor här. Vi har två villkor här, och vi lägger till operatorn 'OCH' mellan dessa villkor, så den returnerar endast de villkor som uppfyller båda villkoren. Det första villkoret vi har lagt till här är 'poäng > 20' och sedan placera '&' operatorn och det andra villkoret som är 'Ut == 9'.
Så det kommer att filtrera de data där lagets poäng är mindre än 20 och även deras outs är 9. Den filtrerar dessa och ignorerar de återstående, vilket inte kommer att uppfylla båda villkoren eller någon av dem. Vi visar också de data som uppfyller båda villkoren, så vi har använt metoden 'print ()'.
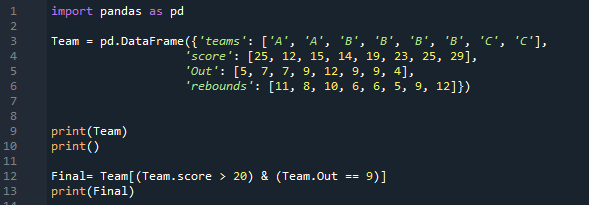
Endast två rader uppfyller båda villkoren, som vi har tillämpat på denna DataFrame. Det filtrerar bara de rader där poängen är större än 20, och deras outs är också 9 och visar dem här.
Exempel 03
I våra ovanstående koder infogar vi bara numeriska data i vår DataFrame. Nu lägger vi in lite strängdata i den här koden. Efter att ha importerat 'pandas som pd' går vi vidare för att bygga en 'Member' DataFrame. Den innehåller fyra unika kolumner. Namnet på den första kolumnen här är 'Namn', och vi infogar namnen på medlemmarna, som är 'Allierade, Bills, Charles, David, Ethen, George och Henry'. Nästa kolumn heter 'Location' här och den har 'America. Kanada, Europa, Kanada, Tyskland, Dubai och Kanada” i den. Kolumnen 'Kod' innehåller 'W, W, W, E, E, E och E'. Vi lägger också till 'poäng' för medlemmarna här som '11, 6, 10, 8, 6, 5 och 12'. Vi återger 'Member' DataFrame med användning av 'print ()'-metoden. Vi har specificerat några villkor i denna DataFrame.
Här har vi två villkor, och genom att lägga till 'OCH'-operatorn mellan dem kommer den bara att returnera villkor som uppfyller båda villkoren. Här är det första villkoret som vi har infört 'Plats == Kanada', följt av operatorn '&', och det andra villkoret, 'pekar <= 9'. Den hämtar dessa data från DataFrame där båda villkoren är uppfyllda, och sedan har vi placerat 'print ()' som visar de data där båda villkoren är sanna.
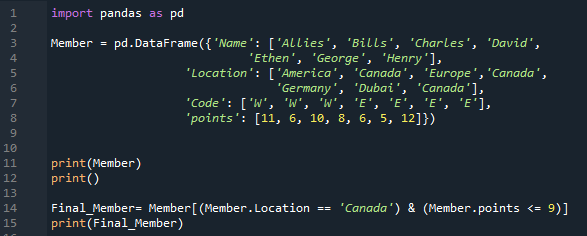
Nedan kan du märka att två rader extraheras från DataFrame och visas. På båda raderna är platsen 'Kanada' och poängen är mindre än 9.
Exempel 04
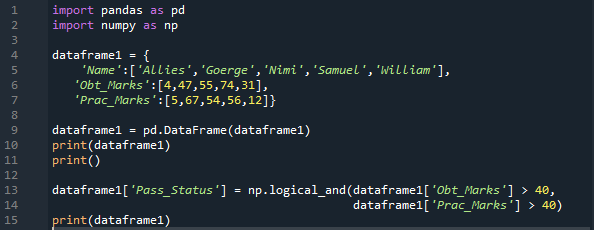
Vi importerar både 'pandas' och 'numpy' här som 'pd' respektive 'np'. Vi får 'pandas'-metoderna genom att placera 'pd' och 'numpy'-metoderna genom att placera 'np' där det behövs. Då innehåller ordboken vi har skapat här tre kolumner. I kolumnen 'Namn' där vi infogar 'Allierade, George, Nimi, Samuel och William'. Därefter har vi kolumnen 'Obt_Marks', som innehåller de erhållna betygen från eleverna, och dessa betyg är '4, 47, 55, 74 och 31'.
Vi skapar också en kolumn för 'Prac_Marks' här som har studentens praktiska betyg. De märken vi lägger till här är '5, 67, 54, 56 och 12'. Vi gör dataramen för denna ordbok och skriver ut den. Vi tillämpar 'np.Logical_and' här, vilket kommer att returnera resultatet i 'True' eller 'False' form. Vi lagrar även resultatet efter att ha kontrollerat båda villkoren i en ny kolumn, som vi har skapat här med namnet 'Pass_Status'.
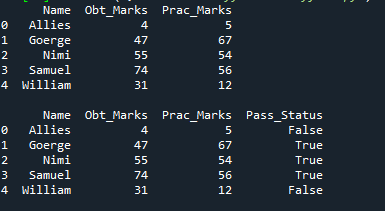
Den kontrollerar att 'Obt_Marks' är större än '40' och 'Prac_Marks' är större än '40'. Om båda är sanna, kommer det att göras sant i den nya kolumnen; annars blir det falskt.
Den nya kolumnen läggs till med namnet 'Pass_Status', och denna kolumn består endast av 'True' och 'False'. Det stämmer när de erhållna poängen och även de praktiska poängen är större än 40 och falska för de återstående raderna.
Slutsats
Den här handledningens huvudsakliga mål är att förklara begreppet 'och tillstånd' i 'pandas'. Vi har pratat om hur man skaffar de rader där båda villkoren är uppfyllda, eller så blir vi sanna för de där alla villkor är uppfyllda och falska för de återstående. Vi har utforskat fyra exempel här. Alla fyra exemplen som vi har etablerat i den här handledningen har gått igenom den här processen. Exemplen i denna handledning har alla presenterats eftertänksamt för din fördel. Denna handledning borde hjälpa dig att förstå denna idé tydligare.