Hur använder man Pandas fallutlåtande?
Fallutlåtanden kan skapas på flera sätt. Funktionen NumPy where(), som använder följande grundläggande syntax, är det enklaste sättet att konstruera en case-sats i en Pandas DataFrame:
df [ 'kolumnnamn' ] = np.var ( skick 1 , 'värde1',np.var ( skick två , 'värde2',
np.var ( skick 3 , 'värde3', 'värde4' ) ) )
Ovanstående uttalande kommer att kontrollera varje villkor för värdet och, om villkoret är uppfyllt, kommer det att generera utdata eller returnera värdet mot villkoret.
Exempel # 1: Pandas Case Statement Använder where()-funktionen
Låt oss skapa en dataram först så att vi kan använda vår fallbeskrivning. För att skapa dataramen kommer vi först att importera modulerna numpy och pandas så att vi kan använda deras funktioner. pd.Dataframe() kommer att användas för att skapa vår dataram.

Vi har skapat 'df'-dataramen. En Python-ordbok skickas inuti pd.DataFrame() fungerar som ett argument med nycklar och värden. Vi kommer att använda funktionen print() för att se vår dataram.
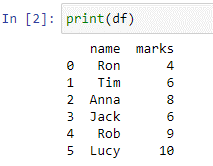
I 'df'-dataramen har vi två kolumner 'namn' och 'markeringar' med värdena ['Ron', 'Tim', 'Anna', 'Jack', 'Rob', 'Lucy'] och [4, 6 8, 6, 9, 10] respektive. Anta att namnet är kolumnerna som lagrar namnen på eleverna och kolumnen 'marker' lagrar poängen från något nyligen genomfört test. Nu kommer vi att skriva en fallbeskrivning som lägger till en ny kolumn med namnet 'anmärkningar' vars värden är baserade på de värden som specificerats av oss, för varje villkor.

Metoden 'numpy.where()' tillhandahåller elementindex från en inmatningsmatris, kolumn eller lista som uppfyller det angivna villkoret. I växlingsfallet ovan kontrollerar funktionen np.where() varje element i 'marks'-kolumnerna. Om värdet är lika med eller mindre än 5, kommer det att returnera 'fail' som en utgång. Om värdet är mindre än eller lika med 7, kommer det att returnera tillfredsställande, och om värdet är mindre än eller lika med 9, kommer det att returnera 'bra'. Om det inte finns några, kommer resultatet att bli utmärkt.
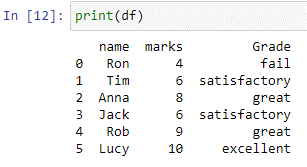
Som kan noteras skapas den nya kolumnen 'kommentarer' i vår 'df'-dataram, och lagrar de värden som returneras av falluttrycket ovan.
Exempel #2:
Låt oss försöka ovanstående fallsats igen med en annan dataram. Anta att vi måste betygsätta spelare baserat på deras totala mål i den föregående fotbollsturneringen. Så låt oss skapa en dataram för att lagra fotbollsspelares register.
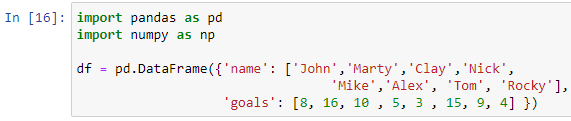
Vi har passerat en ordbok med nycklarna 'name' och 'goals' inuti funktionen pd.DataFrame() för att skapa vår dataram. För att skriva ut vår dataram kommer vi att använda utskriftsfunktionen.
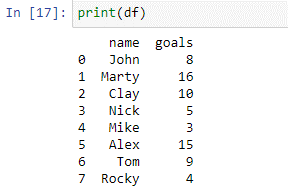
Som kan ses i ovanstående dataram har vi två kolumner: 'namn' och 'mål'. I kolumnnamnet har vi namnen på spelarna ['John', 'Marty', 'Clay', 'Nick', 'Mike', 'Alex', 'Tom', 'Rocky']. I 'kolumnmålen' har vi det totala antalet mål som gjorts av varje spelare i den föregående turneringen. Vi kommer nu att använda vårt fallbeskrivning för att betygsätta dessa spelare baserat på de mål de har gjort.

Ovanstående fall skapas med hjälp av where()-funktionen. Inuti fallet kontrollerar uttalandefunktionen varje element i 'marks'-kolumnerna mot villkoren. Om värdet i kolumnen 'mål' är lika med eller mindre än 5, kommer det att returnera 'C'. Om värdet i kolumnen 'mål' är lika med eller mindre än 9, kommer det att returnera 'B'. Det kommer att returnera ett 'A' om värdet i kolumnen 'mål' är lika med eller större än 10. Värdena som returneras av uttalandet kommer att lagras i den nya kolumnen 'betyg'. Låt oss skriva ut 'df' för att se resultaten.
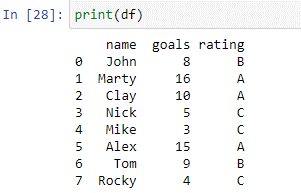
Den nya kolumnen 'betyg' har skapats med skriptet ovan.
Exempel # 3: Pandas if-else Statement Använder funktionen applicera()
Dataramens rad- eller kolumnaxel används av metoden apply() för att implementera en funktion. Vi kan skapa vår egen definierade funktion och använda den i vår dataram i pandor. Det kommer att omfatta if-else-villkor. Låt oss skapa vår dataram först, sedan skapar vi en funktion där vi kommer att använda en if-else-sats för att generera resultatet. För att skapa vår dataram kommer vi först att importera pandornas modul, sedan skickar vi en ordbok i pd.DataFrame()-metoden.
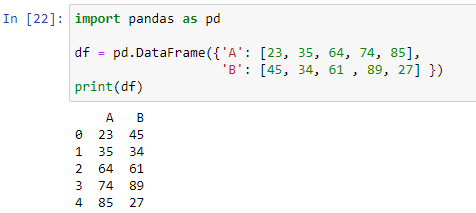
Som kan ses består vår dataram av två kolumner 'A' som lagrar numeriska värden [23, 35, 64, 74, 85] och 'B' med värden [45, 34, 61, 89, 27]. Nu kommer vi att skapa en funktion som kommer att avgöra vilket värde som är större bland båda kolumnerna i varje rad i vår dataram.
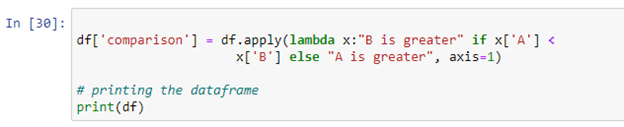
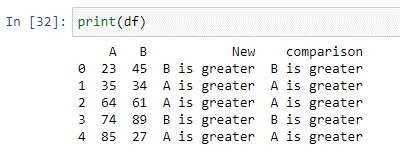
Du kan använda Python lambda-funktionen 'pandas. DataFrame.apply()' för att köra ett uttryck. I Python är en lambda-funktion en kompakt anonym funktion som accepterar valfritt antal argument och exekverar ett uttryck. I skriptet ovan har vi skapat en villkorssats som kommer att jämföra värdet för båda kolumnerna och lagra resultatet i den nya 'jämförelse'-kolumnen. Om värdet på kolumn 'A' är mindre än värdet på kolumn 'B' kommer det att returnera 'B är större'. Om villkoret inte är uppfyllt kommer det att returnera 'A är större'.
Exempel #4:
Låt oss prova ett annat exempel med if-else-satsen inuti funktionen apply() med en annan dataram.
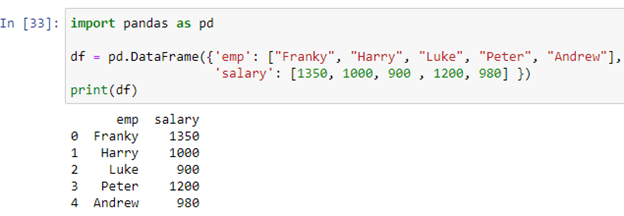
Anta att vår dataram lagrar register över anställda i något företag. Kolumnen 'emp' lagrar namnen på anställda ['Franky', 'Harry', 'Luke', 'Peter', 'Andrew'], medan kolumnen 'lön' lagrar lönerna för varje anställd [1350, 1000, 900 , 1200, 980] i 'df'-dataramen. Nu kommer vi att skapa vår if-else-sats med metoden apply().

Ovanstående villkor kommer att kontrollera för varje värde i kolumnen 'lön' och lägga till 200 till lönerna för anställda där lönevärdet är mindre än eller lika med 1000. Vi har lagrat värdena som returneras från funktionen applicera() i den nya kolumnen ' ökning'. Låt oss se resultaten från skriptet ovan.
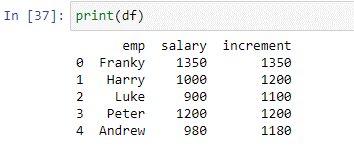
Som du kan se har funktionen framgångsrikt lagt till 200 till värdena som var mindre än eller lika med 100. Värdena som var större än 1000 förblev oförändrade.
Slutsats:
I den här handledningen har vi sett att när villkoret är uppfyllt returnerar ett uttalande av denna typ, som kallas en case-sats, ett värde. Vi har sett hur du kan skapa en ärendebeskrivning för att utföra en nödvändig operation eller uppgift. I den här handledningen har vi använt funktionen np.where() och funktionen apply() för att skapa fallsatser. Vi implementerade några exempel för att lära dig hur du använder pandas case-satser genom att använda where()-funktionen och hur du använder applicera()-funktionen för att skapa case-satser.