Hur fungerar gruppaggregation i MongoDB?
Operatorn $group ska användas för att gruppera indatadokumenten enligt det angivna _id-uttrycket. Den ska sedan returnera ett enda dokument med de totala värdena för varje separat grupp. Till att börja med implementeringen har vi skapat samlingen 'Böcker' i MongoDB. Efter skapandet av 'Böcker'-samlingen har vi infogat de dokument som är kopplade till de olika fälten. Dokumenten infogas i samlingen via metoden insertMany() eftersom frågan som ska köras visas nedan.
>db.Books.insertMany([{
_id:1,
titel: 'Anna Karenina',
pris: 290,-
år: 1879,
order_status: 'I lager',
författare: {
'name': 'Leo Tolstoy'
}
},
{
_id:2,
titel: 'To Kill a Mockingbird',
pris: 500:-
år: 1960,
order_status: 'slut i lager',
författare: {
'name': 'Harper Lee'
}
},
{
_id:3,
titel: 'Osynlig man',
pris: 312,-
år: 1953,
order_status: 'I lager',
författare: {
'name': 'Ralph Ellison'
}
},
{
_id:4,
titel: 'Älskade',
pris: 370,-
år: 1873,
order_status: 'out_of_stock',
författare: {
'name': 'Toni Morrison'
}
},
{
_id:5,
titel: 'Saker faller samman',
pris: 200,-
år: 1958,
order_status: 'I lager',
författare: {
'name':'Chinua Achebe'
}
},
{
_id:6,
titel: 'The Color Purple',
pris: 510,-
år: 1982,
order_status: 'slut i lager',
författare: {
'name': 'Alice Walker'
}
}
])
Dokumenten lagras framgångsrikt i samlingen 'Böcker' utan att stöta på några fel eftersom utdata bekräftas som 'sant'. Nu kommer vi att använda dessa dokument i 'Böcker'-samlingen för att utföra '$group'-aggregationen.

Exempel # 1: Användning av $group Aggregation
Den enkla användningen av $group-aggregationen visas här. Den aggregerade frågan matar först in operatorn '$group' och sedan tar operatorn '$group' uttrycken för att generera de grupperade dokumenten.
>db.Books.aggregate([
{ $grupp:{ _id:'$author.name'} }
])
Frågan ovan för $group-operatorn specificeras med fältet '_id' för att beräkna de totala värdena för alla indatadokument. Sedan tilldelas '_id'-fältet '$author.name' som bildar en annan grupp i '_id'-fältet. De separata värdena för $author.name kommer att returneras eftersom vi inte beräknar några ackumulerade värden. Körningen av $group aggregate-frågan har följande utdata. Fältet _id har värden för författare.namn.

Exempel # 2: Användning av $group Aggregation med $push Accumulator
Exemplet med $group-aggregation använder vilken ackumulator som helst som redan nämnts ovan. Men vi kan använda ackumulatorerna i $group-aggregation. Akkumulatoroperatorerna är de som används på andra inmatningsdokumentfält än de som är 'grupperade' under '_id'. Låt oss anta att vi vill trycka in uttryckets fält i en array, då anropas '$push'-ackumulatorn i operatorn '$group'. Exemplet hjälper dig att förstå '$push'-ackumulatorn för '$gruppen' tydligare.
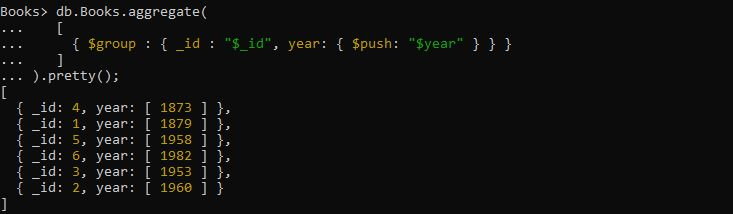
>db.Books.aggregate([
{ $group : { _id : '$_id', år: { $push: '$year' } } }
]
).Söt();
Här vill vi gruppera publiceringsåret för de givna böckerna i arrayen. Ovanstående fråga bör tillämpas för att åstadkomma detta. Aggregeringsfrågan tillhandahålls med uttrycket där operatorn '$group' tar fältuttrycket '_id' och fältuttrycket 'year' för att få gruppåret med hjälp av $push-ackumulatorn. Utdata som hämtas från den här specifika frågan skapar arrayen med årsfält och lagrar det returnerade grupperade dokumentet i det.
Exempel # 3: Användning av $group Aggregation med '$min'-ackumulatorn
Därefter har vi '$min'-ackumulatorn som används i $group-aggregationen för att få det minsta matchningsvärdet från varje dokument i samlingen. Frågeuttrycket för $min-ackumulatorn ges nedan.
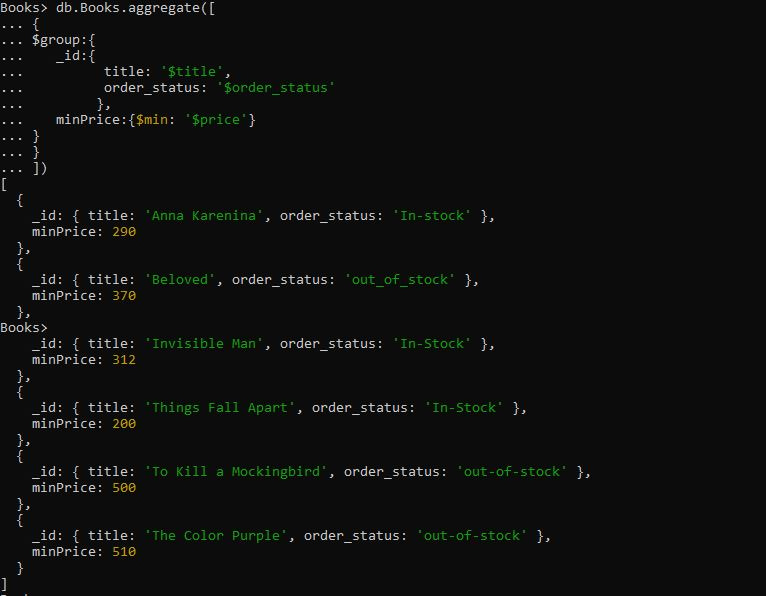
>db.Books.aggregate([{
$group:{
_id:{
title: '$title',
order_status: '$order_status'
},
minPrice:{$min: '$price'}
}
}
])
Frågan har aggregeringsuttrycket '$group' där vi har grupperat dokumentet för fälten 'title' och 'order_status'. Sedan tillhandahöll vi $min-ackumulatorn som grupperade dokumenten genom att hämta minimiprisvärdena från de ogrupperade fälten. När vi kör den här frågan om $min ackumulator nedan returnerar den de grupperade dokumenten efter titel och order_status i en sekvens. Minimipriset visas först och det högsta priset på dokumentet placeras sist.
Exempel # 4: Använd $group Aggregation med $sum Accumulator
För att få summan av alla numeriska fält med $group-operatorn, används $sum-ackumulatoroperationen. De icke-numeriska värdena i samlingarna beaktas av denna ackumulator. Dessutom använder vi $match-aggregationen här med $group-aggregationen. $match-aggregationen accepterar frågevillkoren som ges i ett dokument och skickar det matchade dokumentet till $group-aggregatet som sedan returnerar summan av dokumentet för varje grupp. För $sum-ackumulatorn presenteras frågan nedan.
>db.Books.aggregate([{ $match:{ order_status:'I-Stock'}},
{ $group:{ _id:'$author.name', totalBooks: { $sum:1 } }
}])
Ovanstående fråga om aggregering börjar med $match-operatorn som matchar alla 'order_status' vars status är 'In-Stock' och skickas till $gruppen som indata. Sedan har $gruppoperatorn uttrycket $summaackumulator som matar ut summan av alla böcker i aktien. Observera att '$sum:1' lägger till 1 till varje dokument som tillhör samma grupp. Utdata här visade endast två grupperade dokument som har 'order_status' förknippad med 'In-Stock'.

Exempel # 5: Använd $group Aggregation med $sort Aggregation
Operatorn $group här används med operatorn '$sort' som används för att sortera de grupperade dokumenten. Följande fråga har tre steg till sorteringsoperationen. Först är $match-stadiet, sedan $group-stadiet och sist är $sort-stadiet som sorterar det grupperade dokumentet.
>db.Books.aggregate([{ $match:{ order_status:'out-of-stock'}},
{ $group:{ _id:{ authorName :'$author.name'}, totalBooks: { $sum:1} } },
{ $sort:{ authorName:1}}
])
Här har vi hämtat det matchade dokumentet vars 'order_status' är slut i lager. Sedan matas det matchade dokumentet in i $group-stadiet som grupperade dokumentet med fältet 'authorName' och 'totalBooks'. $group-uttrycket är associerat med $sum-ackumulatorn till det totala antalet 'out-of-stock'-böcker. De grupperade dokumenten sorteras sedan med uttrycket $sort i stigande ordning eftersom '1' här indikerar stigande ordning. Det sorterade gruppdokumentet i angiven ordning erhålls i följande utdata.

Exempel # 6: Använd $group Aggregation för distinkt värde
Aggregeringsproceduren grupperar också dokumenten efter artikel med hjälp av operatorn $group för att extrahera de distinkta artikelvärdena. Låt oss ha frågeuttrycket för detta uttalande i MongoDB.
>db.Books.aggregate( [ { $group : { _id : '$title' } } ] ).pretty();Aggregeringsfrågan tillämpas på boksamlingen för att få det distinkta värdet av gruppdokumentet. $gruppen här tar uttrycket _id som matar ut de distinkta värdena när vi har matat in 'titel'-fältet till den. Utdata från gruppdokumentet erhålls när den här frågan körs som har gruppen med titelnamn mot fältet _id.

Slutsats
Guiden syftade till att rensa konceptet med $group-aggregationsoperatorn för att gruppera dokumentet i MongoDB-databasen. MongoDB:s aggregerade tillvägagångssätt förbättrar grupperingsfenomenen. Syntaxstrukturen för $group-operatorn visas med exempelprogrammen. Utöver det grundläggande exemplet med $gruppoperatorerna har vi även använt denna operator med några ackumulatorer som $push, $min, $sum och operatorer som $match och $sort.