Köl (Knowledge Extraction based on Evolutionary Learning) är ett Java-baserat mjukvaruverktyg som är specialiserat på implementering av evolutionära algoritmer. Eftersom det är en öppen källkod tillhandahåller den en mängd olika kunskapsupptäckandealgoritmer som kan användas i experiment som driver datautvinnings- och analysgemenskapen. Det ger ett enkelt och lättanvänt grafiskt användargränssnitt som avsevärt minskar den övergripande komplexiteten för detta verktyg. De flesta liknande verktyg på marknaden kräver att användarna interagerar med dem genom att skriva koden medan Keel tar bort detta krav genom att tillhandahålla ett intuitivt GUI som kan användas av både nybörjare och experter.
Keel tillhandahåller ett brett utbud av olika beräkningsintelligensbaserade algoritmer inklusive klassificering, regression, funktionsextraktion, mönsteranalys, klustring och mer. Med vanliga modeller inbakade direkt i själva applikationen är Keel ett mycket användbart verktyg när det gäller att utföra utforskande dataanalyser på rådatauppsättningar. Dess enkla dra och släpp-gränssnitt i kombination med enkla funktionalitetsutnyttjande möjliggör snabb och effektiv datautvinningsexperiment för både utbildnings- och forskningsändamål. Verktyg som Keel ökar i popularitet på grund av deras förenklade inställning till annars komplexa algoritmiska metoder.
Installation
Det finns två huvudsakliga sätt på vilka vi kan installera Köl på vilken Linux-maskin som helst. Den första innebär att gå till Köl webbsida och ladda ner programvaran därifrån. Den andra, som vi kommer att följa i den här installationsguiden, kräver att vi laddar ner Keel med hjälp av wget nedladdningsverktyg tillgängligt för Linux-användare.
1. Vi börjar med att få wget på vår Linux-maskin.
Kör följande kommando för att ladda ner wget med hjälp av benägen pakethanterare:
$ sudo apt-get install wget
Du kommer att se en liknande terminalutgång:
2. Nu när vi har wget verktyg installerat på vår Linux-maskin, använder vi det för att ladda ner Köl verktyg.
Det här är länk att vi övergår till wget.
Kör följande kommando i din terminal:
$ wget http: // sci2s.ugr.es / köl / programvara / prototyper / öppen version / Programvara- 2018 -04-09.zip
Du bör se en liknande utgång på din terminal:
När Keel är färdig med nedladdningen kan vi fortsätta med resten av installationen.
3. Vi extraherar nu den komprimerade filen som vi laddade ner i föregående steg med hjälp av Linux Unzip-verktyget.
Kör följande kommando:
$ packa upp Programvara- 2018 -04-09.zip
Du bör se en liknande utgång i terminalen:
4. Navigera till mappen Keel genom att köra följande kommando:
$ CD Programvara- 2018 -04-09 / dokument / experiment / KÖL / dist /
5. Kör följande kommando för att börja med installationen:
$ java -burk . / GraphInterKeel.jar
Med detta bör Keel vara tillgänglig för dig att använda på din Linux-maskin.
Användarguide
Interagerar med Köl applikationen är verkligen enkel och enkel. Låt oss börja med att importera Iris datauppsättning in i vår arbetsplats.
När vi importerar data visar verktyget oss den övergripande klustringen av datapunkten i datamängden. Den visar oss också de olika klasserna som finns i datamängden tillsammans med den grundläggande informationen som de numeriska intervallen som dessa datapunkter spänner över och den övergripande variansen och medelvärdena den presenterar. Denna information gör det möjligt för användarna att bättre förstå hur de ska gå vidare med dataförberedelserna för alla typer av dataanalysuppgifter.
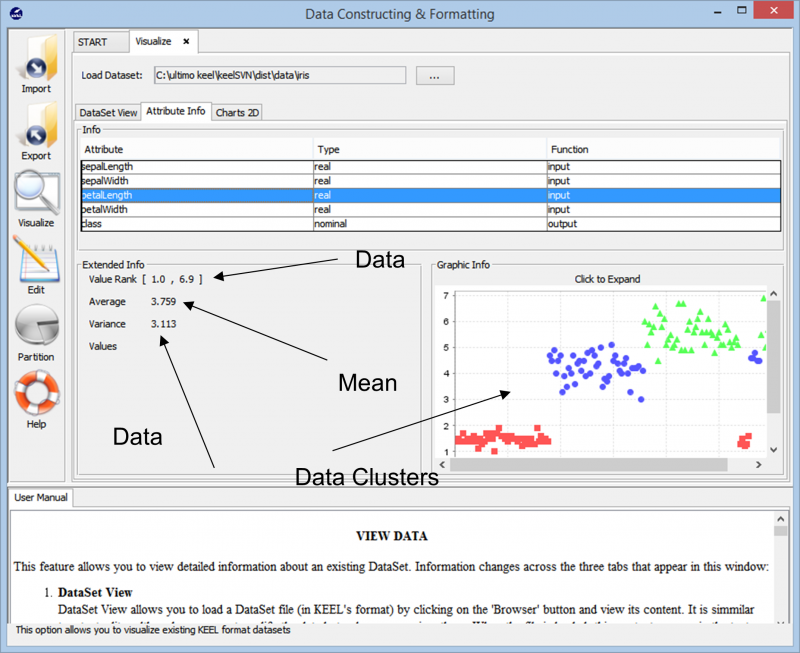
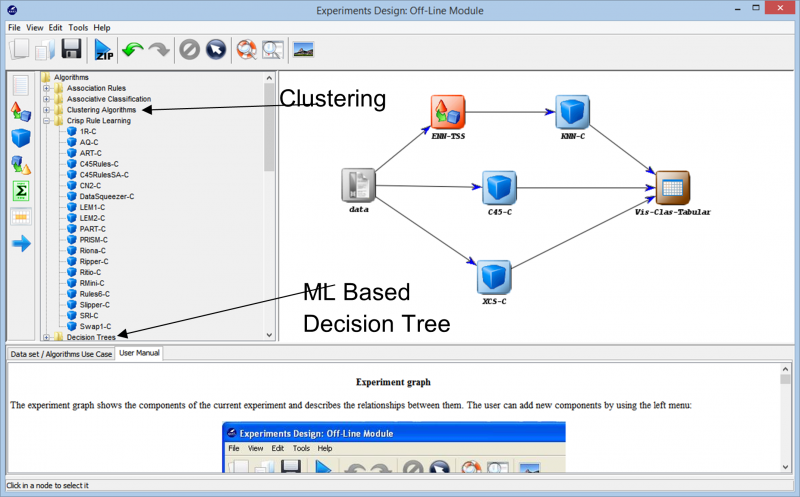
När vi går vidare in i experimentet kommer vi över de olika teknikerna som kan användas för att skapa vårt experiment på vilken datauppsättning som helst. De olika inlärningsalgoritmerna som kan användas på vår data kan ses i följande bild. Beroende på typen av datamängd och kraven på experimentet kan olika algoritmer experimenteras med.
Om du till exempel arbetar med omärkta data och måste hitta likheter mellan de olika datapunkterna i din datamängd, kan en klustringsalgoritm från de olika tillgängliga alternativen hjälpa dig att bättre förstå datapunkterna. Detta hjälper dig så småningom att märka och klassificera datapunkterna så att experimentet kan byggas på med hjälp av mer omfattande övervakade inlärningsalgoritmer.
Slutsats
De Köl plattform för dataanalys är en bra resurs för både forsknings- och utbildningsändamål. Dess lättanvända grafiska användargränssnitt hjälper användarna att bättre förstå datakraven tillsammans med logiska referenser till användbara tekniker och algoritmer som ytterligare hjälper användarna i deras arbetsflöden. Att ha ett brett utbud av olika algoritmer som faller under de olika kategorierna och algoritmiska teknikerna tillåter användarna att experimentera med många logiska riktningar och jämföra dessa resultat så att den mest optimala lösningen på alla problem kan nås.
Keels kodfria dra och släpp-strategi för datautvinning hjälper även nybörjare att utan ansträngning arbeta med omfattande beräkningsintelligensmodeller. Detta ger insikter i komplexa datamängder och leder till användbara slutsatser som hjälper till att lösa de verkliga problemen.