Den här guiden kommer att illustrera processen att använda entitetsminne i LangChain.
Hur man använder enhetsminne i LangChain?
Entiteten används för att hålla nyckelfakta lagrade i minnet för att extrahera när människan tillfrågas med hjälp av frågorna/uppmaningarna. För att lära dig hur man använder enhetsminnet i LangChain, besök helt enkelt följande guide:
Steg 1: Installera moduler
Installera först LangChain-modulen med pip-kommandot för att få dess beroenden:
pip installera langkedja
Installera sedan OpenAI-modulen för att få dess bibliotek för att bygga LLM:er och chattmodeller:
pip installera openai
Ställ in OpenAI-miljön med hjälp av API-nyckeln som kan extraheras från OpenAI-kontot:
importera du
importera getpass
du . ungefär [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
Steg 2: Använda enhetsminne
För att använda entitetsminnet, importera de nödvändiga biblioteken för att bygga LLM med OpenAI()-metoden:
från långkedja. llms importera OpenAIfrån långkedja. minne importera ConversationEntityMemory
llm = OpenAI ( temperatur = 0 )
Efter det definierar du minne variabel som använder metoden ConversationEntityMemory() för att träna modellen med ingångs- och utdatavariabler:
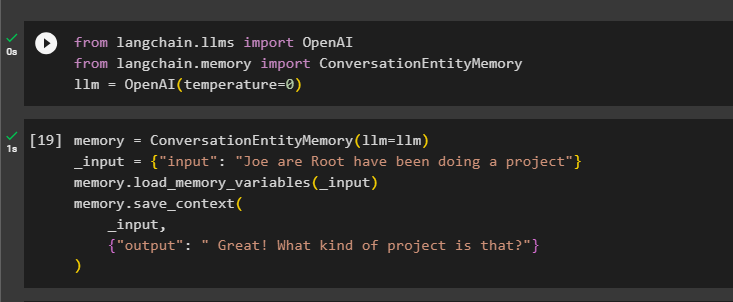
minne = ConversationEntityMemory ( llm = llm )_inmatning = { 'inmatning' : 'Joe are Root har gjort ett projekt' }
minne. load_memory_variables ( _inmatning )
minne. save_context (
_inmatning ,
{ 'produktion' : 'Bra! Vad är det för projekt?' }
)
Testa nu minnet med hjälp av frågan/prompten i inmatning variabel genom att anropa metoden load_memory_variables():
minne. load_memory_variables ( { 'inmatning' : 'vem är root' } ) 
Ge nu lite mer information så att modellen kan lägga till några fler enheter i minnet:
minne = ConversationEntityMemory ( llm = llm , return_messages = Sann )_inmatning = { 'inmatning' : 'Joe are Root har gjort ett projekt' }
minne. load_memory_variables ( _inmatning )
minne. save_context (
_inmatning ,
{ 'produktion' : 'Bra! Vad är det för projekt' }
)
Kör följande kod för att få utdata med hjälp av enheterna som är lagrade i minnet. Det är möjligt genom inmatning som innehåller uppmaningen:
minne. load_memory_variables ( { 'inmatning' : 'vem är Joe' } ) 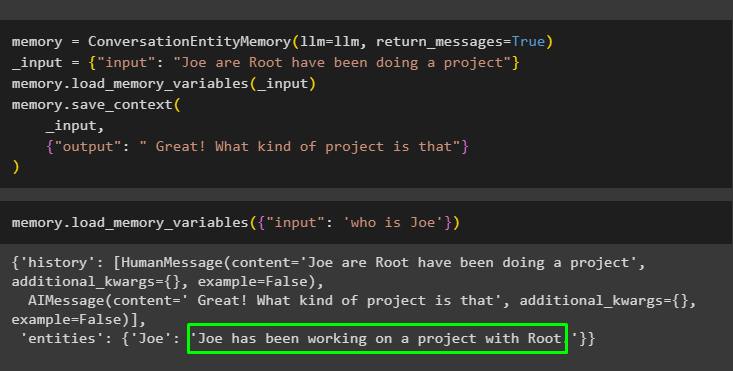
Steg 3: Använda enhetsminne i en kedja
För att använda enhetsminnet efter att ha byggt en kedja, importera helt enkelt de nödvändiga biblioteken med hjälp av följande kodblock:
från långkedja. kedjor importera ConversationChainfrån långkedja. minne importera ConversationEntityMemory
från långkedja. minne . prompt importera ENTITY_MEMORY_CONVERSATION_MALL
från pydantisk importera Basmodell
från skriver importera Lista , Dict , Några
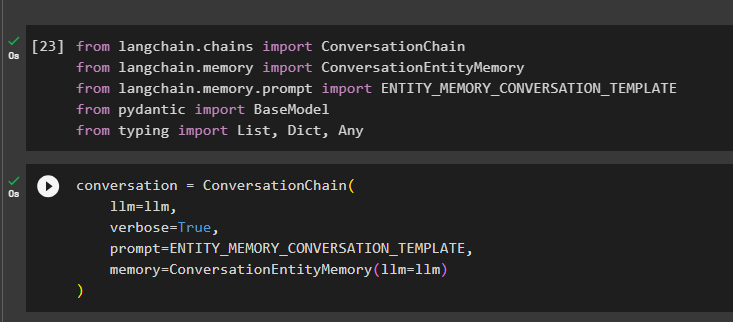
Bygg konversationsmodellen med metoden ConversationChain() med argument som llm:
konversation = ConversationChain (llm = llm ,
mångordig = Sann ,
prompt = ENTITY_MEMORY_CONVERSATION_MALL ,
minne = ConversationEntityMemory ( llm = llm )
)
Anropa metoden conversation.predict() med indata initialiserad med prompten eller frågan:
konversation. förutse ( inmatning = 'Joe are Root har gjort ett projekt' ) 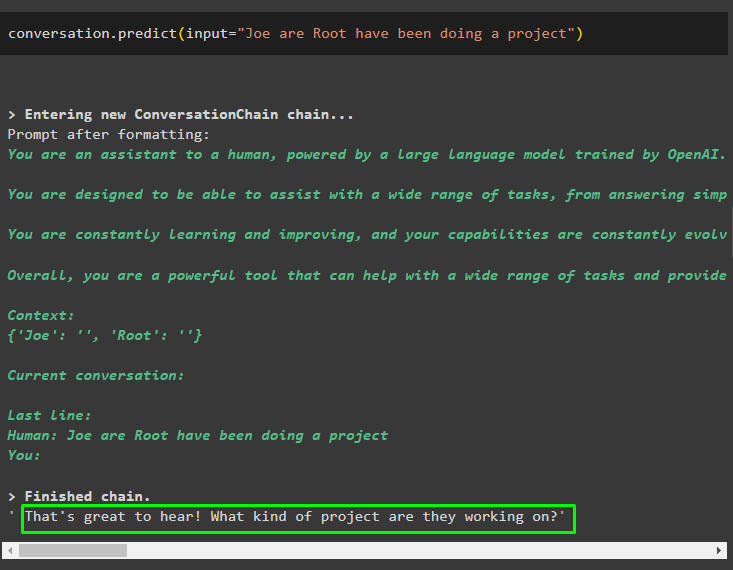
Få nu den separata utdata för varje enhet som beskriver informationen om den:
konversation. minne . entity_store . Lagra 
Använd utdata från modellen för att ge input så att modellen kan lagra mer information om dessa enheter:
konversation. förutse ( inmatning = 'De försöker lägga till mer komplexa minnesstrukturer till Langchain' ) 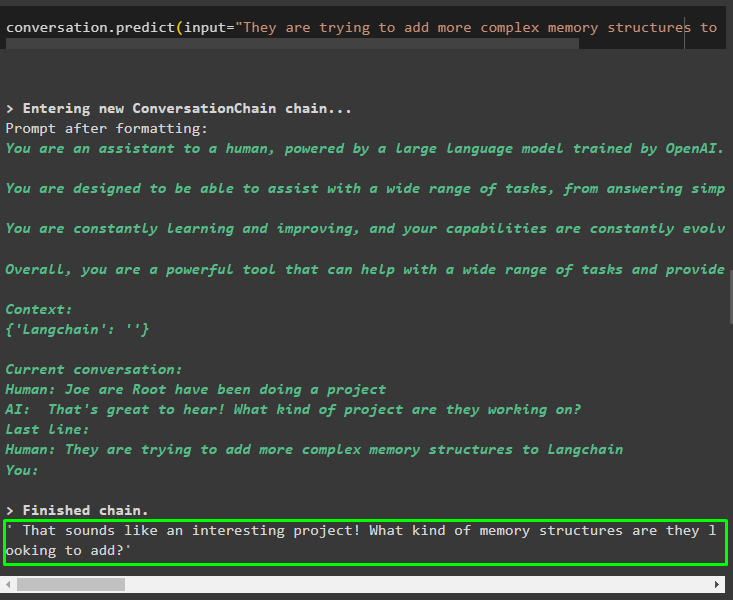
Efter att ha angett informationen som lagras i minnet, ställ helt enkelt frågan för att extrahera den specifika informationen om enheter:
konversation. förutse ( inmatning = 'Vad vet du om Joe och Root' ) 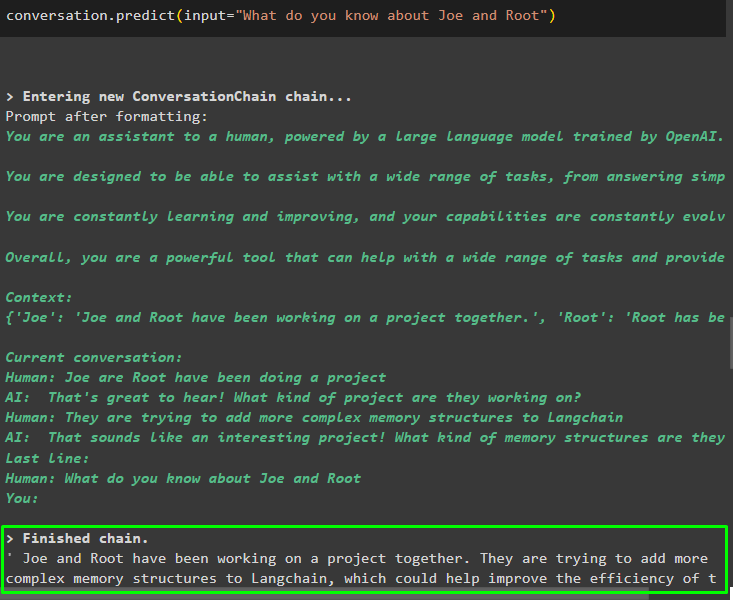
Steg 4: Testa Memory Store
Användaren kan inspektera minneslagringarna direkt för att få informationen lagrad i dem med hjälp av följande kod:
från skriva ut importera skriva utskriva ut ( konversation. minne . entity_store . Lagra )
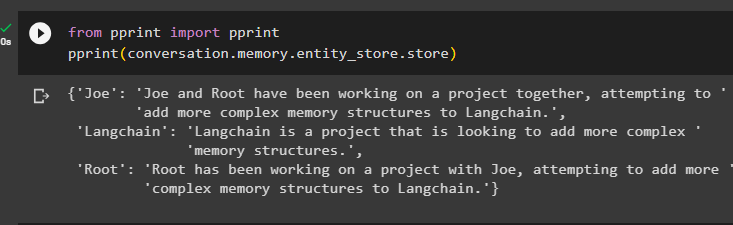
Ge mer information som ska lagras i minnet eftersom mer information ger mer exakta resultat:
konversation. förutse ( inmatning = 'Root har grundat ett företag som heter HJRS' ) 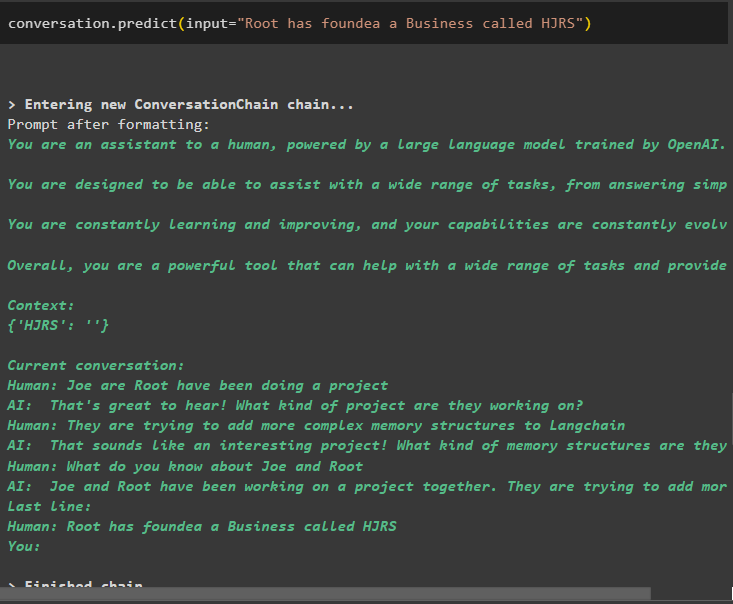
Extrahera information från minnesarkivet efter att ha lagt till mer information om enheterna:
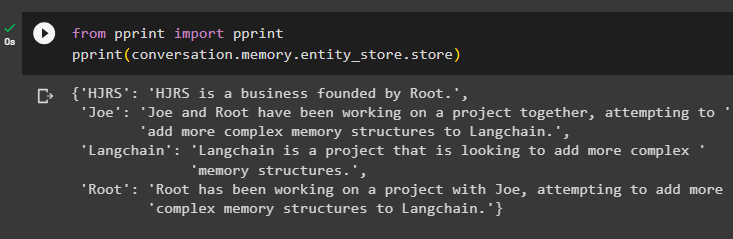
från skriva ut importera skriva utskriva ut ( konversation. minne . entity_store . Lagra )
Minnet har information om flera enheter som HJRS, Joe, LangChain och Root:
Extrahera nu information om en specifik enhet med hjälp av frågan eller prompten som definieras i indatavariabeln:
konversation. förutse ( inmatning = 'Vad vet du om Root' ) 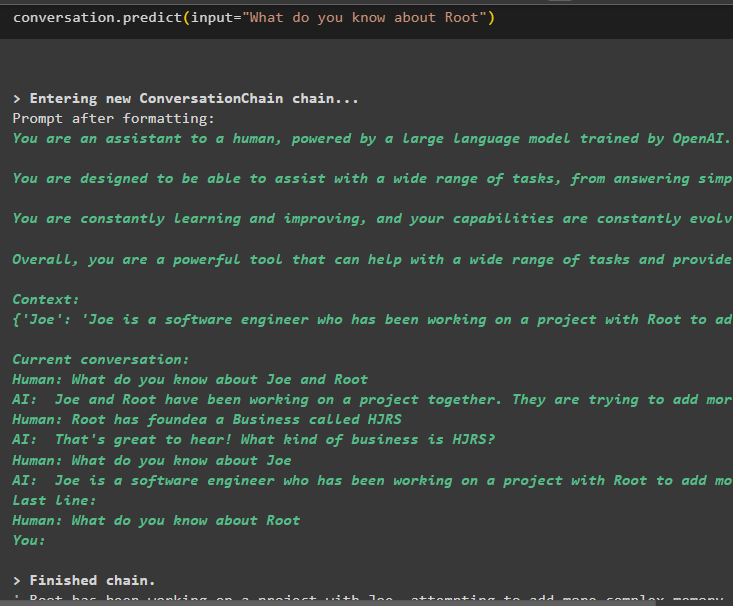
Det handlar om att använda entitetsminnet med hjälp av LangChain-ramverket.
Slutsats
För att använda enhetsminnet i LangChain, installera helt enkelt de nödvändiga modulerna för att importera bibliotek som krävs för att bygga modeller efter att ha konfigurerat OpenAI-miljön. Bygg sedan LLM-modellen och lagra entiteter i minnet genom att tillhandahålla information om entiteterna. Användaren kan också extrahera information med hjälp av dessa entiteter och bygga dessa minnen i kedjorna med omrörd information om entiteter. Det här inlägget har utvecklat processen för att använda enhetsminnet i LangChain.