I R är att få antalet kolumner en grundläggande operation som krävs i många situationer när man arbetar med DataFrames. När du underställer, analyserar, manipulerar, publicerar och visualiserar data är antalet kolumner en viktig del av informationen att känna till. Därför tillhandahåller R olika tillvägagångssätt för att få summan av kolumnerna i den angivna DataFrame. I den här artikeln kommer vi att diskutera några av tillvägagångssätten som hjälper oss att få räkningen av kolumnerna i DataFrame.
Exempel 1: Använda Ncol()-funktionen
ncol() är den vanligaste funktionen för att få summan av kolumnerna i DataFrames.
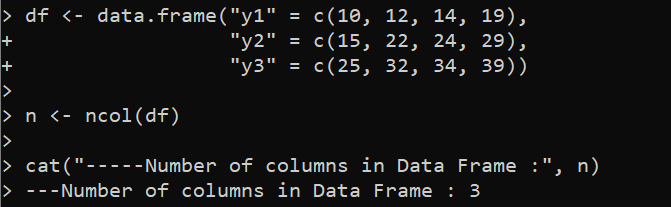
df <- data.frame('y1' = c(10, 12, 14, 19),
'y2' = c(15, 22, 24, 29),
'y3' = c(25, 32, 34, 39))
n <- ncol(df)
cat('-----Antal kolumner i Data Frame :', n)
I det här exemplet skapar vi först en 'df' DataFrame med tre kolumner som är märkta som 'y1', 'y2' och 'y3' med hjälp av data.frame()-funktionen i R. Elementen i varje kolumn specificeras med c()-funktionen som skapar en vektor av element. Sedan, med hjälp av variabeln 'n', används funktionen ncol() för att bestämma summan av kolumner i 'df' DataFrame. Slutligen, med det beskrivande meddelandet och variabeln 'n', skriver den medföljande cat()-funktionen ut resultaten på konsolen.
Som förväntat indikerar den hämtade utdata att den angivna DataFrame har tre kolumner:
Exempel 2: Räkna det totala antalet kolumner för den tomma dataramen
Därefter tillämpar vi funktionen ncol() på den tomma DataFrame som också får värdena för de totala kolumnerna men det värdet är noll.
empty_df <- data.frame()n <- ncol(empty_df)
cat('---Kolumner i dataram :', n)
I det här exemplet genererar vi den tomma DataFrame, 'empty_df', genom att anropa data.frame() utan att ange några kolumner eller rader. Därefter använder vi funktionen ncol() som används för att hitta antalet kolumner i DataFrame. Funktionen ncol() ställs in med 'empty_df' DataFrame här för att få det totala antalet kolumner. Eftersom 'empty_df' DataFrame är tom, har den inga kolumner. Så utdata från ncol(empty_df) är 0. Resultaten visas av funktionen cat() som används här.
Utdata visar värdet '0' som förväntat eftersom DataFrame är tom.

Exempel 3: Använda funktionen Select_If() med funktionen Length()
Om vi vill hämta antalet kolumner av någon specifik typ, bör vi använda funktionen select_if() tillsammans med funktionen length() för R. Dessa funktioner används som kombineras för att få summan av kolumnerna av varje typ . Koden för att använda dessa funktioner implementeras i följande:
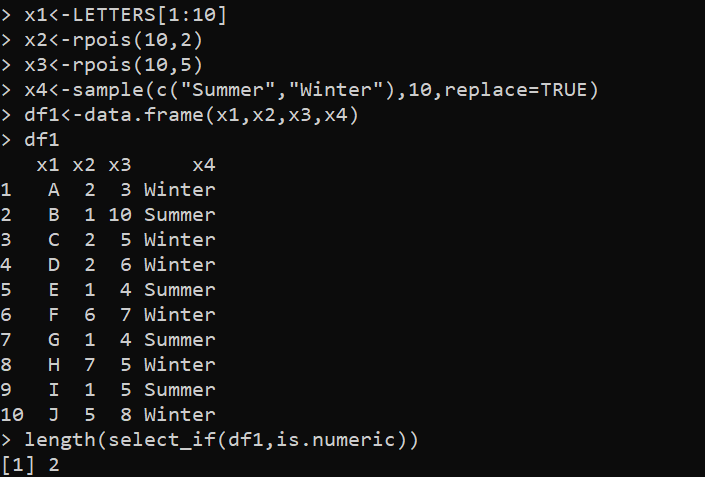
bibliotek (dplyr)x1<-BOKstäver[1:10]
x2<-rpois(10,2)
x3<-rpois(10,5)
x4<-sample(c('Sommar','Vinter'),10,ersätt=TRUE)
df1<-data.frame(x1,x2,x3,x4)
df1
length(select_if(df1,is.numeric))
I det här exemplet laddar vi först dplyr-paketet så att vi kan komma åt funktionen select_if() och funktionen length(). Sedan skapar vi de fyra variablerna - 'x1', 'x2', 'x3' respektive 'x4'. Här innehåller 'x1' de första 10 versalerna i det engelska alfabetet. Variablerna 'x2' och 'x3' genereras med hjälp av funktionen rpois() för att skapa två separata vektorer med 10 slumptal med parametrarna 2 respektive 5. Variabeln 'x4' är en faktorvektor med 10 element som är slumpmässigt samplade från vektor c ('Sommar', 'Vinter').
Sedan försöker vi skapa 'df1' DataFrame där alla variabler skickas i data.frame()-funktionen. Slutligen anropar vi funktionen length() för att bestämma längden på 'df1' DataFrame som skapas med funktionen select_if() från dplyr-paketet. Funktionen select_if() väljer kolumnerna från en 'df1' DataFrame som ett argument och funktionen is.numeric() väljer endast de kolumner som innehåller numeriska värden. Sedan får funktionen length() summan av kolumner som väljs av select_if() som är resultatet av hela koden.
Längden på kolumnen visas i följande utdata som anger det totala antalet kolumner i DataFrame:
Exempel 4: Använda Sapply()-funktionen
Omvänt, om vi bara vill räkna de saknade värdena i kolumnerna, har vi sapply()-funktionen. Funktionen sapply() itererar över varje kolumn i DataFrame för att fungera specifikt. Funktionen sapply() skickas först med DataFrame som argument. Sedan krävs det att operationen utförs på den DataFrame. Implementeringen av sapply()-funktionen för att få antalet NA-värden i DataFrame-kolumnerna tillhandahålls enligt följande:
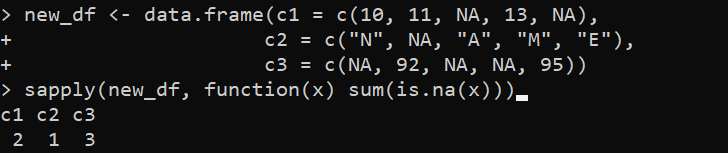
new_df <- data.frame(c1 = c(10, 11, NA, 13, NA),c2 = c('N', NA, 'A', 'M', 'E'),
c3 = c(NA, 92, NA, NA, 95))
sapply(new_df, function(x) summa(is.na(x)))
I det här exemplet genererar vi 'new_df' DataFrame med tre kolumner - 'c1', 'c2' och 'c3'. De första kolumnerna, 'c1' och 'c3', innehåller de numeriska värdena inklusive några saknade värden som representeras av NA. Den andra kolumnen, 'c2', innehåller tecknen inklusive några saknade värden som också representeras av NA. Sedan tillämpar vi sapply()-funktionen på 'new_df' DataFrame och beräknar antalet saknade värden i varje kolumn med hjälp av sum()-uttrycket inuti sapply()-funktionen.
Funktionen is.na() är det uttryck som specificeras för funktionen sum() som returnerar en logisk vektor som indikerar om varje element i kolumnen saknas eller inte. Sum()-funktionen lägger ihop TRUE-värdena för att räkna antalet saknade värden i varje kolumn.
Följaktligen visar utdata de totala NA-värdena i var och en av kolumnerna:
Exempel 5: Använda Dim()-funktionen
Dessutom vill vi få det totala antalet kolumner tillsammans med raderna i DataFrame. Sedan tillhandahåller dim()-funktionen DataFrames dimensioner. Funktionen dim() tar objektet som ett argument vars dimensioner vi vill hämta. Här är koden för att använda dim()-funktionen:
d1 <- data.frame(team=c('t1', 't2', 't3', 't4'),poäng=c(8, 10, 7, 4))
dim(d1)
I det här exemplet definierar vi först 'd1' DataFrame som genereras med hjälp av data.frame()-funktionen där två kolumner är satta 'team' och 'poäng'. Efter det anropar vi funktionen dim() över 'd1' DataFrame. Funktionen dim() returnerar DataFrames antal rader och kolumner. Därför, när vi kör dim(d1), returnerar den en vektor med två element – den första speglar antalet rader i 'd1' DataFrame och den andra representerar antalet kolumner.
Utdata representerar dimensionerna för DataFrame där värdet '4' anger det totala antalet kolumner och värdet '2' representerar raderna:

Slutsats
Vi har nu lärt oss att att räkna antalet kolumner i R är en enkel och viktig operation som kan utföras på DataFrame. Bland alla funktioner är funktionen ncol() det bekvämaste sättet. Nu är vi bekanta med de olika sätten att få antalet kolumner från den givna DataFrame.