Den här artikeln kommer att diskutera hur man använder Elasticsearch multi-get API för att hämta flera JSON-dokument baserat på deras ID:n. Dessutom låter Elasticsearch dig använda en enda få-fråga för att hämta dokumenten från index med endast dokument-ID:n.
Låt oss utforska.
Begär syntax
Följande är syntaxen för Elasticsearch multi-get API:
GET /_mget
GET /
Multi-get API stöder flera index som gör att du kan hämta dokumenten även om de inte finns i samma index.
Begäran stöder följande sökvägsparametrar:
-
– Namnet på indexet från vilket dokumenten ska hämtas enligt deras ID.
Du kan också ange de andra frågeparametrarna som visas:
- Preferens – Definierar den föredragna noden eller skärpan.
- Realtid – Om inställt på sant, utförs operationen i realtid.
- Uppdatera – Tvingar operationen att uppdatera målskärvorna innan de angivna dokumenten hämtas.
- Routing – Ett värde som används för att dirigera operationerna till en specifik skärva.
- Butiksfält – Hämtar dokumentfälten lagrade i ett index istället för dokumentet.
- _källa – Ett booleskt värde som definierar om begäran ska returnera fältet _source eller inte.
Frågan kräver texten, som innehåller följande värden:
- Dokument – Anger de dokument som du vill hämta. Dessutom stöder det här avsnittet följande attribut:
- _id – Unikt ID för måldokumentet.
- _index – Indexet som innehåller måldokumentet.
- Routing – Nyckeln för dokumentets primära skärva.
- _källa – Om sant, inkluderar det alla källfält; annars utesluter det dem.
- _lagrade_fält – De lagrade_fält som du vill inkludera.
- Ids – ID för de dokument som du vill hämta.
Exempel 1: Hämta flera dokument från samma index
Följande exempel visar hur du använder Elasticsearch multi-get API för att hämta dokumenten med specifika ID:n från Netflix index:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Den givna begäran bör hämta dokumenten med de angivna ID:n från Netflix-index. Resultatet är som visas:
{'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'hittad': sant,
'_source': {
'duration': '90 min',
'listed_in': 'Dokumentärer',
'country': 'USA',
'date_added': '25 september 2021',
'show_id': 's1',
'director': 'Kirsten Johnson',
'release_year': 2020,
'rating': 'PG-13',
'description': 'När hennes far närmar sig slutet av sitt liv, iscensätter filmskaparen Kirsten Johnson sin död på uppfinningsrika och komiska sätt för att hjälpa dem båda att möta det oundvikliga.'
'type': 'Film',
'title': 'Dick Johnson är död'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'hittad': sant,
'_source': {
'country': 'Tyskland, Tjeckien',
'show_id': 's13',
'director': 'Christian Schwochow',
'release_year': 2021,
'rating': 'TV-MA',
'description': 'Efter att större delen av hennes familj mördats i en terroristbombning, lockas en ung kvinna omedvetet att ansluta sig till just den grupp som dödade dem.'
'type': 'Film',
'title': 'Jag är Karl',
'duration': '127 min',
'listed_in': 'Dram, internationella filmer',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 september 2021'
}
}
]
}
Vi kan också förenkla begäran genom att lägga dokument-ID:n i en enkel array som visas i följande:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Den tidigare begäran bör utföra en liknande åtgärd.
Exempel 2: Hämta dokumenten från flera index
I följande exempel hämtar begäran flera dokument från olika index som visas:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Resultatet är som visas:

Exempel 3: Exkludera specifika fält
Vi kan exkludera specifika fält från en given begäran med parametrarna source_include och source_exclude.
Ett exempel är som visas:
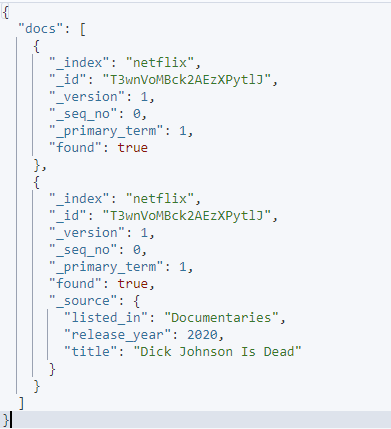
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: rapportering' -H 'Content-Type: application/json' -d'{
'docs': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': false
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'beskrivning', 'typ', 'date_added' ]
}
}
]
}'
Den givna begäran använder källan inkluderar och exkludera för att specificera vilka fält du vill hämta i ett givet dokument.
Resultatet är som visas:
Slutsats
I det här inlägget diskuterade vi grunderna för att arbeta med Elasticsearch multi-get API som låter dig hämta flera dokument från olika källor baserat på deras ID:n. Utforska gärna de andra dokumenten för mer information.
Glad kodning!